Exam Details
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTISTExam Name
:Databricks Certified Professional Data ScientistCertification
:Databricks CertificationsVendor
:DatabricksTotal Questions
:138 Q&AsLast Updated
:Jun 25, 2025
Databricks Databricks Certifications DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Questions & Answers
-
Question 61:
RMSE is a good measure of accuracy, but only to compare forecasting errors of different models for a______, as it is scale-dependent.
A. Between Variables
B. Particular Variable
C. Among all the variables
D. All of the above are correct
-
Question 62:
Select the statement which applies correctly to the Naive Bayes
A. Works with a small amount of data
B. Sensitive to how the input data is prepared
C. Works with nominal values
-
Question 63:
Find out the classifier which assumes independence among all its features?
A. Neural networks
B. Linear Regression
C. Naive Bayes
D. Random forests
-
Question 64:
Which of the following problem you can solve using binomial distribution
A. A manufacturer of metal pistons finds that on the average: 12% of his pistons are rejected because they are either oversize or undersize. What is the probability that a batch of 10 pistons will contain no more than 2 rejects?
B. A life insurance salesman sells on the average 3 life insurance policies per week. Use Poisson's law to calculate the probability that in a given week he will sell Some policies
C. Vehicles pass through a junction on a busy road at an average rate of 300 per hour Find the probability that none passes in a given minute.
D. It was found that the mean length of 100 parts produced by a lathe was 20.05 mm with a standard deviation of 0.02 mm. Find the probability that a part selected at random would have a length between 20.03 mm and 20.08 mm
-
Question 65:
A researcher is interested in how variables, such as GRE (Graduate Record Exam scores), GPA (grade point average) and prestige of the undergraduate institution, effect admission into graduate school. The response variable, admit/don't admit, is a binary variable.
Above is an example of:
A. Linear Regression
B. Logistic Regression
C. Recommendation system
D. Maximum likelihood estimation
E. Hierarchical linear models
-
Question 66:
What is the best way to evaluate the quality of the model found by an unsupervised algorithm like k-means clustering, given metrics for the cost of the clustering (how well it fits the data) and its stability (how similar the clusters are across multiple runs over the same data)?
A. The lowest cost clustering subject to a stability constraint
B. The lowest cost clustering
C. The most stable clustering subject to a minimal cost constraint
D. The most stable clustering
-
Question 67:
Which of the following could be features?
A. Words in the document
B. Symptoms of a diseases
C. Characteristics of an unidentified object
D. 0nly 1 and 2
E. All 1,2 and 3 are possible
-
Question 68:
Suppose A, B , and C are events. The probability of A given B , relative to P(|C), is the same as the probability of A given B and C (relative to P ). That is,
A. P(A,B|C) P(B|C) =P(A|B,C)
B. P(A,B|C) P(B|C) =P(B|A,C)
C. P(A,B|C) P(B|C) =P(C|B,C)
D. P(A,B|C) P(B|C) =P(A|C,B)
-
Question 69:
Your customer provided you with 2. 000 unlabeled records three groups. What is the correct analytical method to use?
A. Semi Linear Regression
B. Logistic regression
C. Naive Bayesian classification
D. Linear regression
E. K-means clustering
-
Question 70:
Consider the following confusion matrix for a data set with 600 out of 11,100 instances positive:
In this case, Precision = 50%, Recall = 83%, Specificity = 95%, and Accuracy = 95%.
Select the correct statement
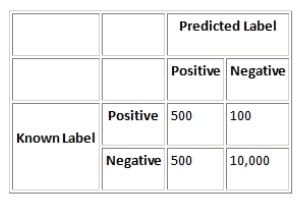
A. Precision is low, which means the classifier is predicting positives best
B. Precision is low, which means the classifier is predicting positives poorly
C. problem domain has a major impact on the measures that should be used to evaluate a classifier within it
D. 1 and 3
E. 2 and 3
Related Exams:
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst AssociateDATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer AssociateDATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer AssociateDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer ProfessionalDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data ScientistDATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning AssociateDATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.