Exam Details
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTISTExam Name
:Databricks Certified Professional Data ScientistCertification
:Databricks CertificationsVendor
:DatabricksTotal Questions
:138 Q&AsLast Updated
:Jun 25, 2025
Databricks Databricks Certifications DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Questions & Answers
-
Question 131:
A data scientist is asked to implement an article recommendation feature for an on-line magazine.
The magazine does not want to use client tracking technologies such as cookies or reading history. Therefore, only the style and subject matter of the current article is available for making recommendations. All of the magazine's articles are stored in a database in a format suitable for analytics.
Which method should the data scientist try first?
A. K Means Clustering
B. Naive Bayesian
C. Logistic Regression
D. Association Rules
-
Question 132:
What is one modeling or descriptive statistical function in MADlib that is typically not provided in a standard relational database?
A. Expected value
B. Variance
C. Linear regression
D. Quantiles
-
Question 133:
You have modeled the datasets with 5 independent variables called A,B,C,D and E having relationships which is not dependent each other, and also the variable A,B and C are continuous and variable D and E are discrete (mixed mode).
Now you have to compute the expected value of the variable let say A, then which of the following computation you will prefer?
A. Integration
B. Differentiation
C. Transformation
D. Generalization
-
Question 134:
Select the correct objectives of principal component analysis:
A. To reduce the dimensionality of the data set
B. To identify new meaningful underlying variables
C. To discover the dimensionality of the data set
D. Only 1 and 2
E. All 1, 2 and 3
-
Question 135:
You are asked to create a model to predict the total number of monthly subscribers for a specific magazine. You are provided with 1 year's worth of subscription and payment data, user demographic data, and 10 years worth of content of the magazine (articles and pictures). Which algorithm is the most appropriate for building a predictive model for subscribers?
A. Linear regression
B. Logistic regression
C. Decision trees
D. TF-IDF
-
Question 136:
You are creating a regression model with the input income, education and current debt of a customer, what could be the possible output from this model?
A. Customer fit as a good
B. Customer fit as acceptable or average category
C. expressed as a percent, that the customer will default on a loan
D. 1 and 3 are correct
E. 2 and 3 are correct
-
Question 137:
Refer to the exhibit.
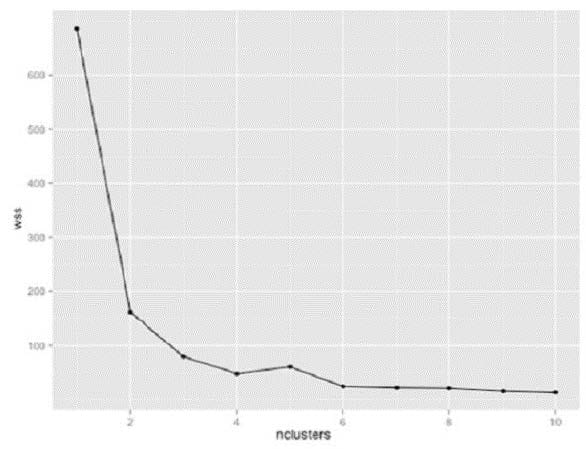
You are using K-means clustering to classify customer behavior for a large retailer. You need to determine the optimum number of customer groups. You plot the within-sum-of- squares (wss) data as shown in the exhibit. How many customer groups should you specify?
A. 2
B. 3
C. 4
D. 8
-
Question 138:
Which of the following are advantages of the Support Vector machines?
A. Effective in high dimensional spaces.
B. it is memory efficient
C. possible to specify custom kernels
D. Effective in cases where number of dimensions is greater than the number of samples
E. Number of features is much greater than the number of samples, the method still give good performances
F. SVMs directly provide probability estimates


Related Exams:
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst AssociateDATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer AssociateDATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer AssociateDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer ProfessionalDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data ScientistDATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning AssociateDATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.