Exam Details
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTISTExam Name
:Databricks Certified Professional Data ScientistCertification
:Databricks CertificationsVendor
:DatabricksTotal Questions
:138 Q&AsLast Updated
:Jun 25, 2025
Databricks Databricks Certifications DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Questions & Answers
-
Question 121:

May have a trend component that is quadratic in nature. Which pattern of data will indicate that the trend in the time series data is quadratic in nature?
A. Naive Bayesian classifier
B. Decision tree
C. Linear regression
D. K-means clustering
-
Question 122:
Select the correct option from the below:
A. If you're trying to predict or forecast a target value^ then you need to look into supervised learning.
B. If you've chosen supervised learning, with discrete target value like Yes/No. 1/2/3, A/B/C: or Red/Yellow/Black, then look into classification.
C. If the target value can take on a number of values, say any value from 0.00 to 100.00, or -999 to 999: or +_to -_, then you need to look unsupervised learning
D. If you're not trying to predict a target value, then you need to look into unsupervised learning
E. Are you trying to fit your data into some discrete groups? If so and that's all you need, you should look into clustering.
-
Question 123:
Feature Hashing approach is "SGD-based classifiers avoid the need to predetermine vector size by simply picking a reasonable size and shoehorning the training data into vectors of that size" now with large vectors or with multiple locations per feature in Feature hashing?
A. Is a problem with accuracy
B. It is hard to understand what classifier is doing
C. It is easy to understand what classifier is doing
D. Is a problem with accuracy as well as hard to understand what classifier us doing
-
Question 124:
Scenario: Suppose that Bob can decide to go to work by one of three modes of transportation, car, bus, or commuter train. Because of high traffic, if he decides to go by car. there is a 50% chance he will be late. If he goes by bus, which has special reserved lanes but is sometimes overcrowded, the probability of being late is only 20%. The commuter train is almost never late, with a probability of only 1 %, but is more expensive than the bus.
Suppose that Bob is late one day, and his boss wishes to estimate the probability that he drove to work that day by car. Since he does not know Which mode of transportation Bob usually uses, he gives a prior probability of 1 3 to each of the three possibilities. Which of the following method the boss will use to estimate of the probability that Bob drove to work?
A. Naive Bayes
B. Linear regression
C. Random decision forests
D. None of the above
-
Question 125:
What type of output generated in case of linear regression?
A. Continuous variable
B. Discrete Variable
C. Any of the Continuous and Discrete variable
D. Values between 0 and 1
-
Question 126:
You are studying the behavior of a population, and you are provided with multidimensional data at the individual level. You have identified four specific individuals who are valuable to your study, and would like to find all users who are most similar to each individual. Which algorithm is the most appropriate for this study?
A. Association rules
B. Decision trees
C. Linear regression
D. K-means clustering
-
Question 127:
You are having 1000 patients' data with the height and age. Where age in years and height in meters. You wanted to create cluster using this two attributes. You wanted to have near equal effect for both the age and height while creating the cluster. What you can do?
A. You will be adding height with the numeric value 100
B. You will be converting each height value to centimeters
C. You will be dividing both age and height with their respective standard deviation
D. You will be taking square root of height
-
Question 128:
Which of the following statement true with regards to Linear Regression Model?
A. Ordinary Least Square can be used to estimates the parameters in linear model
B. In Linear model, it tries to find multiple lines which can approximate the relationship between the outcome and input variables.
C. Ordinary Least Square is a sum of the individual distance between each point and the fitted line of regression model.
D. Ordinary Least Square is a sum of the squared individual distance between each point and the fitted line of regression model.
-
Question 129:
Spam filtering of the emails is an example of
A. Supervised learning
B. Unsupervised learning
C. Clustering
D. 1 and 3 are correct
E. 2 and 3 are correct
-
Question 130:
A fruit may be considered to be an apple if it is red, round, and about 3" in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the:
A. Presence of the other features.
B. Absence of the other features.
C. Presence or absence of the other features
D. None of the above
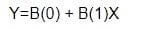
Related Exams:
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst AssociateDATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer AssociateDATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer AssociateDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer ProfessionalDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data ScientistDATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning AssociateDATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.