Exam Details
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTISTExam Name
:Databricks Certified Professional Data ScientistCertification
:Databricks CertificationsVendor
:DatabricksTotal Questions
:138 Q&AsLast Updated
:Jun 25, 2025
Databricks Databricks Certifications DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Questions & Answers
-
Question 81:
Marie is getting married tomorrow, at an outdoor ceremony in the desert. In recent years, it has rained only 5 days each year. Unfortunately, the weatherman has predicted rain for tomorrow. When it actually rains, the weatherman correctly forecasts rain 90% of the time. When it doesn't rain, he incorrectly forecasts rain 10% of the time. Which of the following will you use to calculate the probability whether it will rain on the day of Marie's wedding?
A. Naive Bayes
B. Logistic Regression
C. Random Decision Forests
D. All of the above
-
Question 82:
Suppose that the probability that a pedestrian will be tul by a car while crossing the toad at a pedestrian crossing without paying attention to the traffic light is lo be computed. Let H be a discrete random variable taking one value from (Hit. Not Hit). Let L be a discrete random variable taking one value from (Red. Yellow. Green).
Realistically, H will be dependent on L That is, P(H = Hit) and P(H = Not Hit) will take different values depending on whether L is red, yellow or green. A person is. for example, far more likely to be hit by a car when trying to cross while Hie lights for cross traffic are green than if they are red In other words, for any given possible pair of values for Hand L. one must consider the joint probability distribution of H and L to find the probability* of that pair of events occurring together if Hie pedestrian ignores the state of the light
Here is a table showing the conditional probabilities of being bit. defending on ibe stale of the lights (Note that the columns in this table must add up to 1 because the probability of being hit oi not hit is 1 regardless of the stale of the light.)
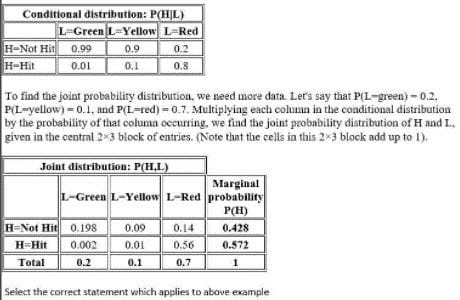
A. The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green.
B. marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
C. marginal probability that P(H=Not Hit) is the sum of the H= Hit row
-
Question 83:
What is the best way to ensure that the k-means algorithm will find a good clustering of a collection of vectors?
A. Only consider values of k larger than log(N), where N is the number of observations in the data set
B. Run at least log(N) iterations of Lloyd's algorithm, where N is the number of observations in the data set
C. Choose the initial centroids so that they all He along different axes
D. Choose the initial centroids so that they are far away from each other
-
Question 84:
Which of the following is a correct example of the target variable in regression (supervised learning)?
A. Nominal values like true, false
B. Reptile, fish, mammal, amphibian, plant, fungi
C. Infinite number of numeric values, such as 0.100, 42.001, 1000.743..
D. All of the above
-
Question 85:
You are using k-means clustering to classify heart patients for a hospital. You have chosen Patient Sex, Height, Weight, Age and Income as measures and have used 3 clusters. When you create a pair-wise plot of the clusters, you notice that there is significant overlap between the clusters. What should you do?
A. Identify additional measures to add to the analysis
B. Remove one of the measures
C. Decrease the number of clusters
D. Increase the number of clusters
-
Question 86:
You are working in a data analytics company as a data scientist, you have been given a set of various types of Pizzas available across various premium food centers in a country. This data is given as numeric values like Calorie. Size, and Sale per day etc. You need to group all the pizzas with the similar properties, which of the following technique you would be using for that?
A. Association Rules
B. Naive Bayes Classifier
C. K-means Clustering
D. Linear Regression
E. Grouping
-
Question 87:
Suppose you have made a model for the rating system, which rates between 1 to 5 stars. And you calculated that RMSE value is 1.0 then which of the following is correct
A. It means that your predictions are on average one star off of what people really think
B. It means that your predictions are on average two star off of what people really think
C. It means that your predictions are on average three star off of what people really think
D. It means that your predictions are on average four star off of what people really think
-
Question 88:
Projecting a multi-dimensional dataset onto which vector has the greatest variance?
A. first principal component
B. first eigenvector
C. not enough information given to answer
D. second eigenvector
E. second principal component
-
Question 89:
You are using one approach for the classification where to teach the agent not by giving explicit categorizations, but by using some sort of reward system to indicate success, where agents might be rewarded for doing certain actions and
punished for doing others.
Which kind of this learning?
A. Supervised
B. Unsupervised
C. Regression
D. None of the above
-
Question 90:
Select the correct statement which applies to K-Nearest Neighbors
A. No Assumption about the data
B. Computationally expensive
C. Require less memory
D. Works with Numeric Values
Related Exams:
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst AssociateDATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer AssociateDATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer AssociateDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer ProfessionalDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data ScientistDATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning AssociateDATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.