DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Exam Details
-
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST -
Exam Name
:Databricks Certified Professional Data Scientist -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:138 Q&As -
Last Updated
:Jul 12, 2026
Databricks DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Online Questions & Answers
-
Question 1:
Select the correct problems which can be solved using SVMs:
A. SVMs are helpful in text and hypertext categorization
B. Classification of images can also be performed using SVMs
C. SVMs are also useful in medical science to classify proteins with up to 90% of the compounds classified correctly
D. Hand-written characters can be recognized using SVM -
Question 2:
You are working as a data science consultant for a gaming company. You have three member team and all other stake holders are from the company itself like project managers and project sponsored, data team etc. During the discussion project managed asked you that when can you tell me that the model you are using is robust enough, after which step you can consider answer for this question?
A. Data Preparation
B. Discovery
C. Operationalize
D. Model planning
E. Model building -
Question 3:
In which of the following scenario we can use naTve Bayes theorem for classification
A. Classify whether a given person is a male or a female based on the measured features. The features include height, weight and foot size.
B. To classify whether an email is spam or not spam
C. To identify whether a fruit is an orange or not based on features like diameter, color and shape -
Question 4:
Your customer provided you with 2. 000 unlabeled records three groups. What is the correct analytical method to use?
A. Semi Linear Regression
B. Logistic regression
C. Naive Bayesian classification
D. Linear regression
E. K-means clustering -
Question 5:
What are the advantages of the Hashing Features?
A. Requires the less memory
B. Less pass through the training data
C. Easily reverse engineer vectors to determine which original feature mapped to a vector location -
Question 6:
Assume some output variable "y" is a linear combination of some independent input variables "A" plus some independent noise "e". The way the independent variables are combined is defined by a parameter vector B y=AB+e where X is an m x n matrix. B is a vector of n unknowns, and b is a vector of m values. Assuming that m is not equal to n and the columns of X are linearly independent, which expression correctly solves for B?
A. Option A
B. Option B
C. Option C
D. Option D -
Question 7:
What describes a true limitation of Logistic Regression method?
A. It does not handle redundant variables well.
B. It does not handle missing values well.
C. It does not handle correlated variables well.
D. It does not have explanatory values. -
Question 8:
Let's say you have two cases as below for the movie ratings
1.
You recommend to a user a movie with four stars and he really doesn't like it and he'd rate it two stars
2.
You recommend a movie with three stars but the user loves it (he'd rate it five stars). So which statement correctly applies?
A. In both cases, the contribution to the RMSE is the same
B. In both cases, the contribution to the RMSE is the different
C. In both cases, the contribution to the RMSE, could varies
D. None of the above -
Question 9:
Which of the following metrics are useful in measuring the accuracy and quality of a recommender system?
A. Cluster Density
B. Support Vector Count
C. Mean Absolute Error
D. Sum of Absolute Errors -
Question 10:
Which of the following statement true with regards to Linear Regression Model?
A. Ordinary Least Square can be used to estimates the parameters in linear model
B. In Linear model, it tries to find multiple lines which can approximate the relationship between the outcome and input variables.
C. Ordinary Least Square is a sum of the individual distance between each point and the fitted line of regression model.
D. Ordinary Least Square is a sum of the squared individual distance between each point and the fitted line of regression model.
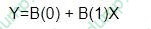
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.