Exam Details
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTISTExam Name
:Databricks Certified Professional Data ScientistCertification
:Databricks CertificationsVendor
:DatabricksTotal Questions
:138 Q&AsLast Updated
:Jun 25, 2025
Databricks Databricks Certifications DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Questions & Answers
-
Question 101:
Assume some output variable "y" is a linear combination of some independent input variables "A" plus some independent noise "e". The way the independent variables are combined is defined by a parameter vector B y=AB+e where X is an m x n matrix. B is a vector of n unknowns, and b is a vector of m values. Assuming that m is not equal to n and the columns of X are linearly independent, which expression correctly solves for B?
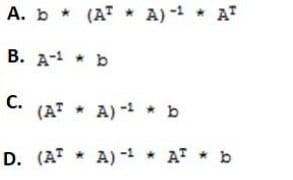
A. Option A
B. Option B
C. Option C
D. Option D
-
Question 102:
What is the probability that the total of two dice will be greater than 8, given that the first die is a 6?
A. 1/3
B. 2/3
C. 1/6
D. 2/6
-
Question 103:
Refer to the Exhibit.
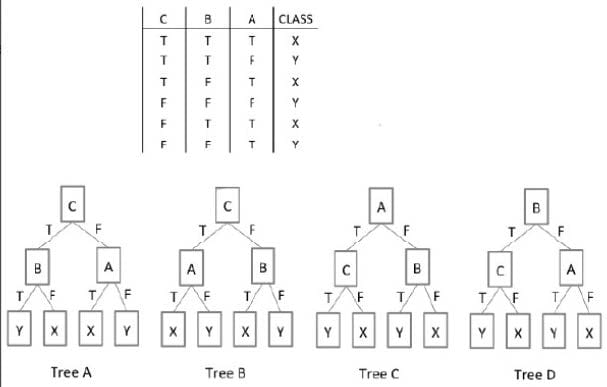
In the Exhibit, the table shows the values for the input Boolean attributes "A", "B", and "C". It also shows the values for the output attribute "class". Which decision tree is valid for the data?
A. Tree A
B. Tree B
C. Tree C
D. Tree D
-
Question 104:
In which of the scenario you can use the regression to predict the values?
A. Samsung can use it for mobile sales forecast
B. Mobile companies can use it to forecast manufacturing defects
C. Probability of the celebrity divorce
D. Only 1 and 2
E. All 1 ,2 and 3
-
Question 105:
You are analyzing data in order to build a classifier model. You discover non-linear data and discontinuities that will affect the model. Which analytical method would you recommend?
A. Logistic Regression
B. Decision Trees
C. Linear Regression
D. ARIMA
-
Question 106:
Select the correct statement which applies to Supervised learning
A. We asks the machine to learn from our data when we specify a target variable.
B. Lesser machine's task to only divining some pattern from the input data to get the target variable
C. Instead of telling the machine Predict Y for our data X, we're asking What can you tell me about X?
-
Question 107:
Of all the smokers in a particular district, 40% prefer brand A and 60% prefer brand B. Of those smokers who prefer brand A. 30% are females, and of those who prefer brand B. 40% are female. What is the probability that a randomly selected smoker prefers brand A, given that the person selected is a female?
Which of the following is a best way to solve this problem?
A. Bays Theorem
B. Poisson Distribution
C. Binomial Distribution
D. None of the above
-
Question 108:
You are building a classifier off of a very high-dimensiona data set similar to shown in the image with 5000 variables (lots of columns, not that many rows). It can handle both dense and sparse input. Which technique is most suitable, and why?
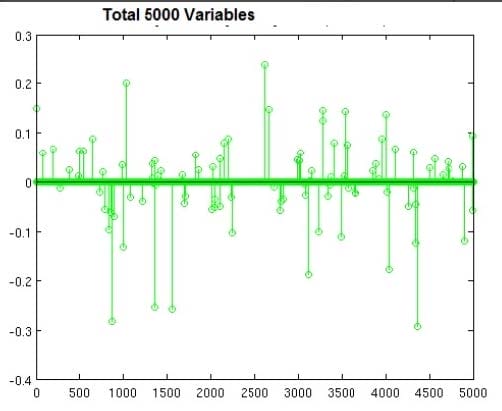
A. Logistic regression with L1 regularization, to prevent overfitting
B. Naive Bayes, because Bayesian methods act as regularlizers
C. k-nearest neighbors, because it uses local neighborhoods to classify examples
D. Random forest because it is an ensemble method
-
Question 109:
If you are trying to predict or forecast a discrete target value, then which is the correct options?
A. Supervised Learning regression algorithms
B. Supervised Learning classification algorithms
C. Un supervised Learning
D. Density estimation algorithm
-
Question 110:
Select the correct algorithm of unsupervised algorithm
A. K-Nearest Neighbors
B. K-Means
C. Support Vector Machines
D. Naive Bayes
Related Exams:
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst AssociateDATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer AssociateDATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer AssociateDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer ProfessionalDATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data ScientistDATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning AssociateDATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.