MLS-C01 Exam Details
-
Exam Code
:MLS-C01 -
Exam Name
:AWS Certified Machine Learning - Specialty (MLS-C01) -
Certification
:Amazon Certifications -
Vendor
:Amazon -
Total Questions
:396 Q&As -
Last Updated
:May 26, 2026
Amazon MLS-C01 Online Questions & Answers
-
Question 311:
A data scientist must build a custom recommendation model in Amazon SageMaker for an online retail company. Due to the nature of the company's products, customers buy only 4-5 products every 5-10 years. So, the company relies on a steady stream of new customers. When a new customer signs up, the company collects data on the customer's preferences. Below is a sample of the data available to the data scientist.

How should the data scientist split the dataset into a training and test set for this use case?
A. Shuffle all interaction data. Split off the last 10% of the interaction data for the test set.
B. Identify the most recent 10% of interactions for each user. Split off these interactions for the test set.
C. Identify the 10% of users with the least interaction data. Split off all interaction data from these users for the test set.
D. Randomly select 10% of the users. Split off all interaction data from these users for the test set. -
Question 312:
A machine learning (ML) specialist is running an Amazon SageMaker hyperparameter optimization job for a model that is based on the XGBoost algorithm. The ML specialist selects Root Mean Square Error (RMSE) as the objective
evaluation metric.
The ML specialist discovers that the model is overfitting and cannot generalize well on the validation data. The ML specialist decides to resolve the model overfitting by using SageMaker automatic model tuning (AMT).
Which solution will meet this requirement?
A. Configure SageMaker AMT to use a static range of hyperparameter values.
B. Configure SageMaker AMT to increase the number of parallel training jobs.
C. Configure SageMaker AMT to stop training jobs early.
D. Configure SageMaker AMT to run the training jobs with a warm start. -
Question 313:
An exercise analytics company wants to predict running speeds for its customers by using a dataset that contains multiple health-related features for each customer. Some of the features originate from sensors that provide extremely noisy values.
The company is training a regression model by using the built-in Amazon SageMaker linear learner algorithm to predict the running speeds. While the company is training the model, a data scientist observes that the training loss decreases to almost zero, but validation loss increases.
Which technique should the data scientist use to optimally fit the model?
A. Add L1 regularization to the linear learner regression model.
B. Perform a principal component analysis (PCA) on the dataset. Use the linear learner regression model.
C. Perform feature engineering by including quadratic and cubic terms. Train the linear learner regression model.
D. Add L2 regularization to the linear learner regression model. -
Question 314:
A company is using Amazon Polly to translate plaintext documents to speech for automated company announcements However company acronyms are being mispronounced in the current documents How should a Machine Learning Specialist address this issue for future documents'?
A. Convert current documents to SSML with pronunciation tags
B. Create an appropriate pronunciation lexicon.
C. Output speech marks to guide in pronunciation
D. Use Amazon Lex to preprocess the text files for pronunciation -
Question 315:
A manufacturing company asks its Machine Learning Specialist to develop a model that classifies defective parts into one of eight defect types. The company has provided roughly 100000 images per defect type for training During the injial training of the image classification model the Specialist notices that the validation accuracy is 80%, while the training accuracy is 90% It is known that human-level performance for this type of image classification is around 90%
What should the Specialist consider to fix this issue1?
A. A longer training time
B. Making the network larger
C. Using a different optimizer
D. Using some form of regularization -
Question 316:
This graph shows the training and validation loss against the epochs for a neural network.
The network being trained is as follows:
1.Two dense layers, one output neuron
2.100 neurons in each layer
3.100 epochs
4.Random initialization of weights
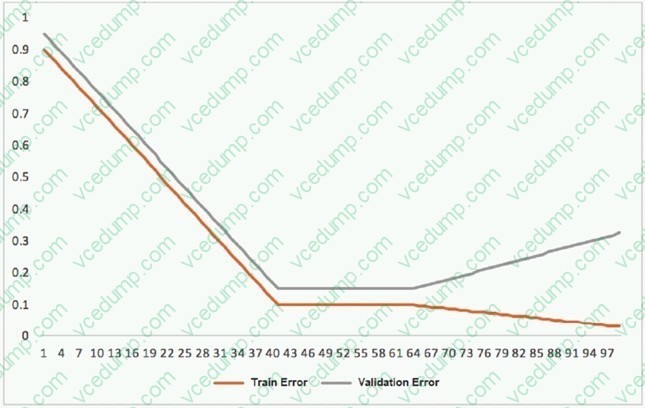
Which technique can be used to improve model performance in terms of accuracy in the validation set?
A. Early stopping
B. Random initialization of weights with appropriate seed
C. Increasing the number of epochs
D. Adding another layer with the 100 neurons -
Question 317:
An ecommerce company is collecting structured data and unstructured data from its website, mobile apps, and IoT devices. The data is stored in several databases and Amazon S3 buckets. The company is implementing a scalable repository to store structured data and unstructured data. The company must implement a solution that provides a central data catalog, self-service access to the data, and granular data access policies and encryption to protect the data.
Which combination of actions will meet these requirements with the LEAST amount of setup? (Choose three.)
A. Identify the existing data in the databases and S3 buckets. Link the data to AWS Lake Formation.
B. Identify the existing data in the databases and S3 buckets. Link the data to AWS Glue.
C. Run AWS Glue crawlers on the linked data sources to create a central data catalog.
D. Apply granular access policies by using AWS Identity and Access Management (IAM). Configure server-side encryption on each data source.
E. Apply granular access policies and encryption by using AWS Lake Formation.
F. Apply granular access policies and encryption by using AWS Glue. -
Question 318:
A data scientist is conducting exploratory data analysis (EDA) on a dataset that contains information about product suppliers. The dataset records the country where each product supplier is located as a two-letter text code. For example, the
code for New Zealand is "NZ."
The data scientist needs to transform the country codes for model training. The data scientist must choose the solution that will result in the smallest increase in dimensionality. The solution must not result in any information loss.
Which solution will meet these requirements?
A. Add a new column of data that includes the full country name.
B. Encode the country codes into numeric variables by using similarity encoding.
C. Map the country codes to continent names.
D. Encode the country codes into numeric variables by using one-hot encoding. -
Question 319:
A manufacturing company wants to create a machine learning (ML) model to predict when equipment is likely to fail. A data science team already constructed a deep learning model by using TensorFlow and a custom Python script in a local environment. The company wants to use Amazon SageMaker to train the model.
Which TensorFlow estimator configuration will train the model MOST cost-effectively?
A. Turn on SageMaker Training Compiler by adding compiler_config=TrainingCompilerConfig() as a parameter. Pass the script to the estimator in the call to the TensorFlow fit() method.
B. Turn on SageMaker Training Compiler by adding compiler_config=TrainingCompilerConfig() as a parameter. Turn on managed spot training by setting the use_spot_instances parameter to True. Pass the script to the estimator in the call to the TensorFlow fit() method.
C. Adjust the training script to use distributed data parallelism. Specify appropriate values for the distribution parameter. Pass the script to the estimator in the call to the TensorFlow fit() method.
D. Turn on SageMaker Training Compiler by adding compiler_config=TrainingCompilerConfig() as a parameter. Set the MaxWaitTimeInSeconds parameter to be equal to the MaxRuntimeInSeconds parameter. Pass the script to the estimator in the call to the TensorFlow fit() method. -
Question 320:
This graph shows the training and validation loss against the epochs for a neural network
The network being trained is as follows
1. Two dense layers one output neuron
2.100 neurons in each layer
4. Random initialization of weights
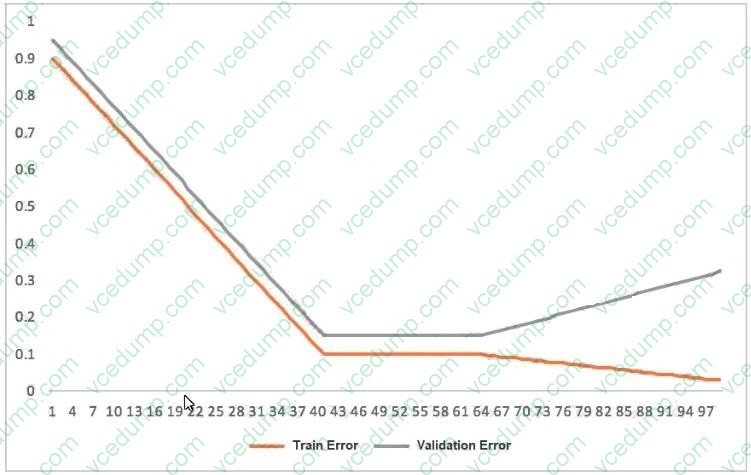
3.100 epochs
Which technique can be used to improve model performance in terms of accuracy in the validation set?
A. Early stopping
B. Random initialization of weights with appropriate seed
C. Increasing the number of epochs
D. Adding another layer with the 100 neurons
Related Exams:
-
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01) -
AIP-C01
AWS Certified Generative AI Developer - Professional -
ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00) -
ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01) -
AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01) -
BDS-C00
AWS Certified Big Data - Speciality (BDS-C00) -
CLF-C02
AWS Certified Cloud Practitioner (CLF-C02) -
DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01) -
DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01) -
DBS-C01
AWS Certified Database - Specialty (DBS-C01)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MLS-C01 exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.