MLS-C01 Exam Details
-
Exam Code
:MLS-C01 -
Exam Name
:AWS Certified Machine Learning - Specialty (MLS-C01) -
Certification
:Amazon Certifications -
Vendor
:Amazon -
Total Questions
:396 Q&As -
Last Updated
:Jul 15, 2026
Amazon MLS-C01 Online Questions & Answers
-
Question 11:
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class distribution for these features is illustrated in the figure provided.
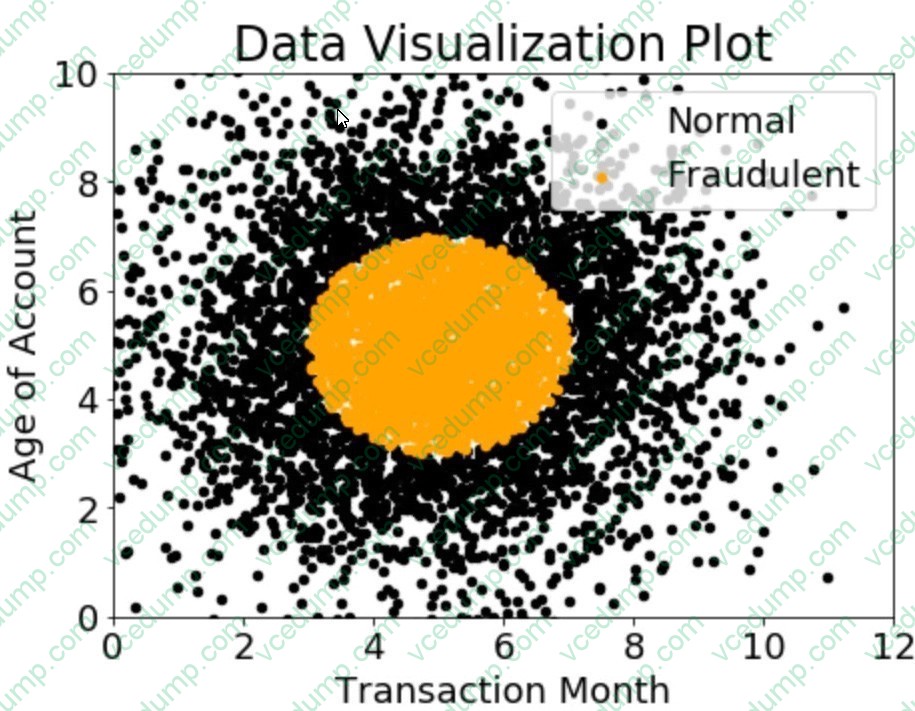
Based on this information, which model would have the HIGHEST accuracy?
A. Long short-term memory (LSTM) model with scaled exponential linear unit (SELL))
B. Logistic regression
C. Support vector machine (SVM) with non-linear kernel
D. Single perceptron with tanh activation function -
Question 12:
A manufacturing company has structured and unstructured data stored in an Amazon S3 bucket. A Machine Learning Specialist wants to use SQL to run queries on this data. Which solution requires the LEAST effort to be able to query this data?
A. Use AWS Data Pipeline to transform the data and Amazon RDS to run queries.
B. Use AWS Glue to catalogue the data and Amazon Athena to run queries.
C. Use AWS Batch to run ETL on the data and Amazon Aurora to run the queries.
D. Use AWS Lambda to transform the data and Amazon Kinesis Data Analytics to run queries. -
Question 13:
The Chief Editor for a product catalog wants the Research and Development team to build a machine learning system that can be used to detect whether or not individuals in a collection of images are wearing the company's retail brand The team has a set of training data.
Which machine learning algorithm should the researchers use that BEST meets their requirements?
A. Latent Dirichlet Allocation (LDA)
B. Recurrent neural network (RNN)
C. K-means
D. Convolutional neural network (CNN) -
Question 14:
A company is observing low accuracy while training on the default built-in image classification algorithm in Amazon SageMaker. The Data Science team wants to use an Inception neural network architecture instead of a ResNet architecture. Which of the following will accomplish this? (Select TWO.)
A. Customize the built-in image classification algorithm to use Inception and use this for model training.
B. Create a support case with the SageMaker team to change the default image classification algorithm to Inception.
C. Bundle a Docker container with TensorFlow Estimator loaded with an Inception network and use this for model training.
D. Use custom code in Amazon SageMaker with TensorFlow Estimator to load the model with an Inception network and use this for model training.
E. Download and apt-get install the inception network code into an Amazon EC2 instance and use this instance as a Jupyter notebook in Amazon SageMaker. -
Question 15:
A Machine Learning Specialist is attempting to build a linear regression model.
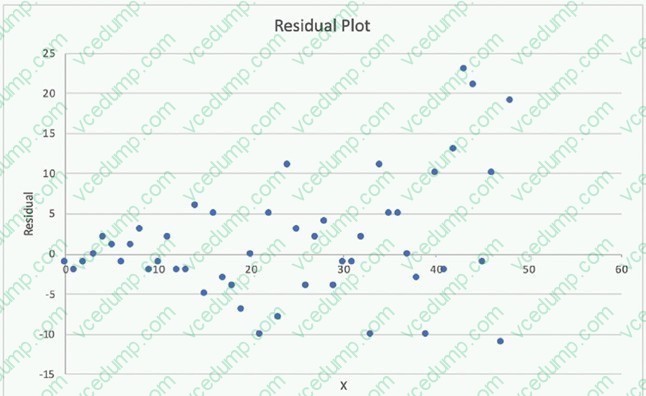
Given the displayed residual plot only, what is the MOST likely problem with the model?
A. Linear regression is inappropriate. The residuals do not have constant variance.
B. Linear regression is inappropriate. The underlying data has outliers.
C. Linear regression is appropriate. The residuals have a zero mean.
D. Linear regression is appropriate. The residuals have constant variance. -
Question 16:
A sports broadcasting company is planning to introduce subtitles in multiple languages for a live broadcast. The commentary is in English. The company needs the transcriptions to appear on screen in French or Spanish, depending on the broadcasting country. The transcriptions must be able to capture domain-specific terminology, names, and locations based on the commentary context. The company needs a solution that can support options to provide tuning data.
Which combination of AWS services and features will meet these requirements with the LEAST operational overhead? (Choose two.)
A. Amazon Transcribe with custom vocabularies
B. Amazon Transcribe with custom language models
C. Amazon SageMaker Seq2Seq
D. Amazon SageMaker with Hugging Face Speech2Text
E. Amazon Translate -
Question 17:
A Machine Learning Specialist is using Amazon SageMaker to host a model for a highly available customer-facing application.
The Specialist has trained a new version of the model, validated it with historical data, and now wants to deploy it to production To limit any risk of a negative customer experience, the Specialist wants to be able to monitor the model and roll it
back, if needed.
What is the SIMPLEST approach with the LEAST risk to deploy the model and roll it back, if needed?
A. Create a SageMaker endpoint and configuration for the new model version. Redirect production traffic to the new endpoint by updating the client configuration. Revert traffic to the last version if the model does not perform as expected.
B. Create a SageMaker endpoint and configuration for the new model version. Redirect production traffic to the new endpoint by using a load balancer Revert traffic to the last version if the model does not perform as expected.
C. Update the existing SageMaker endpoint to use a new configuration that is weighted to send 5% of the traffic to the new variant. Revert traffic to the last version by resetting the weights if the model does not perform as expected.
D. Update the existing SageMaker endpoint to use a new configuration that is weighted to send 100% of the traffic to the new variant Revert traffic to the last version by resetting the weights if the model does not perform as expected. -
Question 18:
A Machine Learning Specialist at a company sensitive to security is preparing a dataset for model training. The dataset is stored in Amazon S3 and contains Personally Identifiable Information (Pll). The dataset:
1.Must be accessible from a VPC only.
2.Must not traverse the public internet. How can these requirements be satisfied?
A. Create a VPC endpoint and apply a bucket access policy that restricts access to the given VPC endpoint and the VPC.
B. Create a VPC endpoint and apply a bucket access policy that allows access from the given VPC endpoint and an Amazon EC2 instance.
C. Create a VPC endpoint and use Network Access Control Lists (NACLs) to allow traffic between only the given VPC endpoint and an Amazon EC2 instance.
D. Create a VPC endpoint and use security groups to restrict access to the given VPC endpoint and an Amazon EC2 instance. -
Question 19:
A real-estate company is launching a new product that predicts the prices of new houses. The historical data for the properties and prices is stored in .csv format in an Amazon S3 bucket. The data has a header, some categorical fields, and some missing values. The company's data scientists have used Python with a common open-source library to fill the missing values with zeros. The data scientists have dropped all of the categorical fields and have trained a model by using the open-source linear regression algorithm with the default parameters.
The accuracy of the predictions with the current model is below 50%. The company wants to improve the model performance and launch the new product as soon as possible.
Which solution will meet these requirements with the LEAST operational overhead?
A. Create a service-linked role for Amazon Elastic Container Service (Amazon ECS) with access to the S3 bucket. Create an ECS cluster that is based on an AWS Deep Learning Containers image. Write the code to perform the feature engineering. Train a logistic regression model for predicting the price, pointing to the bucket with the dataset. Wait for the training job to complete. Perform the inferences.
B. Create an Amazon SageMaker notebook with a new IAM role that is associated with the notebook. Pull the dataset from the S3 bucket. Explore different combinations of feature engineering transformations, regression algorithms, and hyperparameters. Compare all the results in the notebook, and deploy the most accurate configuration in an endpoint for predictions.
C. Create an IAM role with access to Amazon S3, Amazon SageMaker, and AWS Lambda. Create a training job with the SageMaker built-in XGBoost model pointing to the bucket with the dataset. Specify the price as the target feature. Wait for the job to complete. Load the model artifact to a Lambda function for inference on prices of new houses.
D. Create an IAM role for Amazon SageMaker with access to the S3 bucket. Create a SageMaker AutoML job with SageMaker Autopilot pointing to the bucket with the dataset. Specify the price as the target attribute. Wait for the job to complete. Deploy the best model for predictions. -
Question 20:
A company is training machine learning (ML) models on Amazon SageMaker by using 200 TB of data that is stored in Amazon S3 buckets. The training data consists of individual files that are each larger than 200 MB in size. The company needs a data access solution that offers the shortest processing time and the least amount of setup.
Which solution will meet these requirements?
A. Use File mode in SageMaker to copy the dataset from the S3 buckets to the ML instance storage.
B. Create an Amazon FSx for Lustre file system. Link the file system to the S3 buckets.
C. Create an Amazon Elastic File System (Amazon EFS) file system. Mount the file system to the training instances.
D. Use FastFile mode in SageMaker to stream the files on demand from the S3 buckets.
Related Exams:
-
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01) -
AIP-C01
AWS Certified Generative AI Developer - Professional -
ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00) -
ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01) -
AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01) -
BDS-C00
AWS Certified Big Data - Speciality (BDS-C00) -
CLF-C02
AWS Certified Cloud Practitioner (CLF-C02) -
DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01) -
DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01) -
DBS-C01
AWS Certified Database - Specialty (DBS-C01)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MLS-C01 exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.