MLS-C01 Exam Details
-
Exam Code
:MLS-C01 -
Exam Name
:AWS Certified Machine Learning - Specialty (MLS-C01) -
Certification
:Amazon Certifications -
Vendor
:Amazon -
Total Questions
:396 Q&As -
Last Updated
:May 26, 2026
Amazon MLS-C01 Online Questions & Answers
-
Question 331:
An ecommerce company wants to update a production real-time machine learning (ML) recommendation engine API that uses Amazon SageMaker. The company wants to release a new model but does not want to make changes to applications that rely on the API. The company also wants to evaluate the performance of the new model in production traffic before the company fully rolls out the new model to all users.
Which solution will meet these requirements with the LEAST operational overhead?
A. Create a new SageMaker endpoint for the new model. Configure an Application Load Balancer (ALB) to distribute traffic between the old model and the new model.
B. Modify the existing endpoint to use SageMaker production variants to distribute traffic between the old model and the new model.
C. Modify the existing endpoint to use SageMaker batch transform to distribute traffic between the old model and the new model.
D. Create a new SageMaker endpoint for the new model. Configure a Network Load Balancer (NLB) to distribute traffic between the old model and the new model. -
Question 332:
A Machine Learning Specialist is developing a custom video recommendation model for an application. The dataset used to train this model is very large with millions of data points and is hosted in an Amazon S3 bucket. The Specialist wants to avoid loading all of this data onto an Amazon SageMaker notebook instance because it would take hours to move and will exceed the attached 5 GB Amazon EBS volume on the notebook instance.
Which approach allows the Specialist to use all the data to train the model?
A. Load a smaller subset of the data into the SageMaker notebook and train locally. Confirm that the training code is executing and the model parameters seem reasonable. Initiate a SageMaker training job using the full dataset from the S3 bucket using Pipe input mode.
B. Launch an Amazon EC2 instance with an AWS Deep Learning AMI and attach the S3 bucket to the instance. Train on a small amount of the data to verify the training code and hyperparameters. Go back to Amazon SageMaker and train using the full dataset
C. Use AWS Glue to train a model using a small subset of the data to confirm that the data will be compatible with Amazon SageMaker. Initiate a SageMaker training job using the full dataset from the S3 bucket using Pipe input mode.
D. Load a smaller subset of the data into the SageMaker notebook and train locally. Confirm that the training code is executing and the model parameters seem reasonable. Launch an Amazon EC2 instance with an AWS Deep Learning AMI and attach the S3 bucket to train the full dataset. -
Question 333:
A medical device company is building a machine learning (ML) model to predict the likelihood of device recall based on customer data that the company collects from a plain text survey. One of the survey questions asks which medications the customer is taking. The data for this field contains the names of medications that customers enter manually. Customers misspell some of the medication names. The column that contains the medication name data gives a categorical feature with high cardinality but redundancy.
What is the MOST effective way to encode this categorical feature into a numeric feature?
A. Spell check the column. Use Amazon SageMaker one-hot encoding on the column to transform a categorical feature to a numerical feature.
B. Fix the spelling in the column by using char-RNN. Use Amazon SageMaker Data Wrangler one-hot encoding to transform a categorical feature to a numerical feature.
C. Use Amazon SageMaker Data Wrangler similarity encoding on the column to create embeddings Of vectors Of real numbers.
D. Use Amazon SageMaker Data Wrangler ordinal encoding on the column to encode categories into an integer between O and the total number Of categories in the column. -
Question 334:
A company wants to predict the classification of documents that are created from an application. New documents are saved to an Amazon S3 bucket every 3 seconds. The company has developed three versions of a machine learning (ML) model within Amazon SageMaker to classify document text. The company wants to deploy these three versions to predict the classification of each document.
Which approach will meet these requirements with the LEAST operational overhead?
A. Configure an S3 event notification that invokes an AWS Lambda function when new documents are created. Configure the Lambda function to create three SageMaker batch transform jobs, one batch transform job for each model for each document.
B. Deploy all the models to a single SageMaker endpoint. Treat each model as a production variant. Configure an S3 event notification that invokes an AWS Lambda function when new documents are created. Configure the Lambda function to call each production variant and return the results of each model.
C. Deploy each model to its own SageMaker endpoint Configure an S3 event notification that invokes an AWS Lambda function when new documents are created. Configure the Lambda function to call each endpoint and return the results of each model.
D. Deploy each model to its own SageMaker endpoint. Create three AWS Lambda functions. Configure each Lambda function to call a different endpoint and return the results. Configure three S3 event notifications to invoke the Lambda functions when new documents are created. -
Question 335:
A Data Scientist is building a linear regression model and will use resulting p-values to evaluate the statistical significance of each coefficient. Upon inspection of the dataset, the Data Scientist discovers that most of the features are normally distributed. The plot of one feature in the dataset is shown in the graphic.
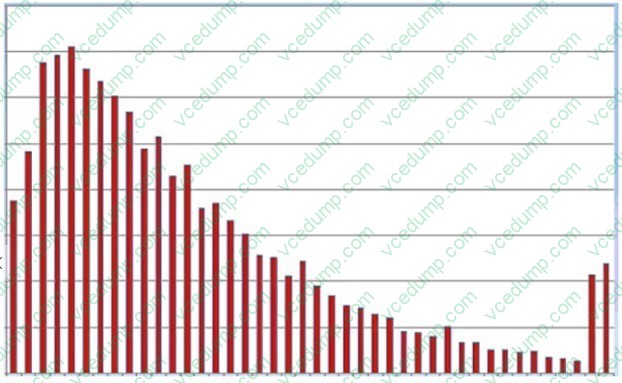
What transformation should the Data Scientist apply to satisfy the statistical assumptions of the linear regression model?
A. Exponential transformation
B. Logarithmic transformation
C. Polynomial transformation
D. Sinusoidal transformation -
Question 336:
A machine learning (ML) engineer is preparing a dataset for a classification model. The ML engineer notices that some continuous numeric features have a significantly greater value than most other features. A business expert explains that the features are independently informative and that the dataset is representative of the target distribution.
After training, the model's inferences accuracy is lower than expected.
Which preprocessing technique will result in the GREATEST increase of the model's inference accuracy?
A. Normalize the problematic features.
B. Bootstrap the problematic features.
C. Remove the problematic features.
D. Extrapolate synthetic features. -
Question 337:
A company maintains a 2 TB dataset that contains information about customer behaviors. The company stores the dataset in Amazon S3. The company stores a trained model container in Amazon Elastic Container Registry (Amazon ECR).
A machine learning (ML) specialist needs to score a batch model for the dataset to predict customer behavior. The ML specialist must select a scalable approach to score the model.
Which solution will meet these requirements MOST cost-effectively?
A. Score the model by using AWS Batch managed Amazon EC2 Reserved Instances. Create an Amazon EC2 instance store volume and mount it to the Reserved Instances.
B. Score the model by using AWS Batch managed Amazon EC2 Spot Instances. Create an Amazon FSx for Lustre volume and mount it to the Spot Instances.
C. Score the model by using an Amazon SageMaker notebook on Amazon EC2 Reserved Instances. Create an Amazon EBS volume and mount it to the Reserved Instances.
D. Score the model by using Amazon SageMaker notebook on Amazon EC2 Spot Instances. Create an Amazon Elastic File System (Amazon EFS) file system and mount it to the Spot Instances. -
Question 338:
A geospatial analysis company processes thousands of new satellite images each day to produce vessel detection data for commercial shipping. The company stores the training data in Amazon S3. The training data incrementally increases in size with new images each day.
The company has configured an Amazon SageMaker training job to use a single ml.p2.xlarge instance with File input mode to train the built-in Object Detection algorithm. The training process was successful last month but is now failing because of a lack of storage. Aside from the addition of training data, nothing has changed in the model training process.
A machine learning (ML) specialist needs to change the training configuration to fix the problem. The solution must optimize performance and must minimize the cost of training.
Which solution will meet these requirements?
A. Modify the training configuration to use two ml.p2.xlarge instances.
B. Modify the training configuration to use Pipe input mode.
C. Modify the training configuration to use a single ml.p3.2xlarge instance.
D. Modify the training configuration to use Amazon Elastic File System (Amazon EFS) instead of Amazon S3 to store the input training data. -
Question 339:
A company wants to detect credit card fraud. The company has observed that an average of 2% of credit card transactions are fraudulent. A data scientist trains a classifier on a year's worth of credit card transaction data. The classifier needs to identify the fraudulent transactions. The company wants to accurately capture as many fraudulent transactions as possible.
Which metrics should the data scientist use to optimize the classifier? (Choose two.)
A. Specificity
B. False positive rate
C. Accuracy
D. F1 score
E. True positive rate -
Question 340:
A data scientist is training a large PyTorch model by using Amazon SageMaker. It takes 10 hours on average to train the model on GPU instances. The data scientist suspects that training is not converging and that resource utilization is not optimal.
What should the data scientist do to identify and address training issues with the LEAST development effort?
A. Use CPU utilization metrics that are captured in Amazon CloudWatch. Configure a CloudWatch alarm to stop the training job early if low CPU utilization occurs.
B. Use high-resolution custom metrics that are captured in Amazon CloudWatch. Configure an AWS Lambda function to analyze the metrics and to stop the training job early if issues are detected.
C. Use the SageMaker Debugger vanishing_gradient and LowGPUUtilization built-in rules to detect issues and to launch the StopTrainingJob action if issues are detected.
D. Use the SageMaker Debugger confusion and feature_importance_overweight built-in rules to detect issues and to launch the StopTrainingJob action if issues are detected.
Related Exams:
-
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01) -
AIP-C01
AWS Certified Generative AI Developer - Professional -
ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00) -
ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01) -
AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01) -
BDS-C00
AWS Certified Big Data - Speciality (BDS-C00) -
CLF-C02
AWS Certified Cloud Practitioner (CLF-C02) -
DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01) -
DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01) -
DBS-C01
AWS Certified Database - Specialty (DBS-C01)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MLS-C01 exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.