Exam Details
Exam Code
:MLS-C01Exam Name
:AWS Certified Machine Learning - Specialty (MLS-C01)Certification
:Amazon CertificationsVendor
:AmazonTotal Questions
:396 Q&AsLast Updated
:Aug 13, 2025
Amazon Amazon Certifications MLS-C01 Questions & Answers
-
Question 381:
Example Corp has an annual sale event from October to December. The company has sequential sales data from the past 15 years and wants to use Amazon ML to predict the sales for this year's upcoming event. Which method should Example Corp use to split the data into a training dataset and evaluation dataset?
A. Pre-split the data before uploading to Amazon S3
B. Have Amazon ML split the data randomly.
C. Have Amazon ML split the data sequentially.
D. Perform custom cross-validation on the data
-
Question 382:
A bank's Machine Learning team is developing an approach for credit card fraud detection The company has a large dataset of historical data labeled as fraudulent The goal is to build a model to take the information from new transactions and predict whether each transaction is fraudulent or not.
Which built-in Amazon SageMaker machine learning algorithm should be used for modeling this problem?
A. Seq2seq
B. XGBoost
C. K-means
D. Random Cut Forest (RCF)
-
Question 383:
An office security agency conducted a successful pilot using 100 cameras installed at key locations within the main office. Images from the cameras were uploaded to Amazon S3 and tagged using Amazon Rekognition, and the results were stored in Amazon ES. The agency is now looking to expand the pilot into a full production system using thousands of video cameras in its office locations globally. The goal is to identify activities performed by non-employees in real time.
Which solution should the agency consider?
A. Use a proxy server at each local office and for each camera, and stream the RTSP feed to a unique Amazon Kinesis Video Streams video stream. On each stream, use Amazon Rekognition Video and create a stream processor to detect faces from a collection of known employees, and alert when non-employees are detected.
B. Use a proxy server at each local office and for each camera, and stream the RTSP feed to a unique Amazon Kinesis Video Streams video stream. On each stream, use Amazon Rekognition Image to detect faces from a collection of known employees and alert when non-employees are detected.
C. Install AWS DeepLens cameras and use the DeepLens_Kinesis_Video module to stream video to Amazon Kinesis Video Streams for each camera. On each stream, use Amazon Rekognition Video and create a stream processor to detect faces from a collection on each stream, and alert when nonemployees are detected.
D. Install AWS DeepLens cameras and use the DeepLens_Kinesis_Video module to stream video to Amazon Kinesis Video Streams for each camera. On each stream, run an AWS Lambda function to capture image fragments and then call Amazon Rekognition Image to detect faces from a collection of known employees, and alert when non-employees are detected.
-
Question 384:
A manufacturing company asks its Machine Learning Specialist to develop a model that classifies defective parts into one of eight defect types. The company has provided roughly 100000 images per defect type for training During the injial training of the image classification model the Specialist notices that the validation accuracy is 80%, while the training accuracy is 90% It is known that human-level performance for this type of image classification is around 90%
What should the Specialist consider to fix this issue1?
A. A longer training time
B. Making the network larger
C. Using a different optimizer
D. Using some form of regularization
-
Question 385:
A Machine Learning Specialist prepared the following graph displaying the results of k-means for k = [1..10]:
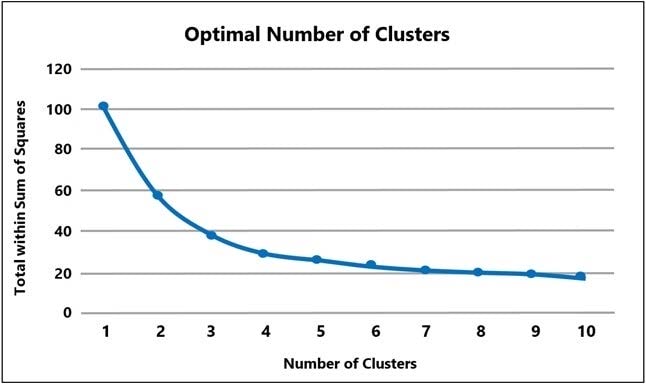
Considering the graph, what is a reasonable selection for the optimal choice of k?
A. 1
B. 4
C. 7
D. 10
-
Question 386:
A Data Scientist is developing a machine learning model to classify whether a financial transaction is fraudulent. The labeled data available for training consists of 100,000 non-fraudulent observations and 1,000 fraudulent observations.
The Data Scientist applies the XGBoost algorithm to the data, resulting in the following confusion matrix when the trained model is applied to a previously unseen validation dataset. The accuracy of the model is 99.1%, but the Data Scientist has been asked to reduce the number of false negatives.
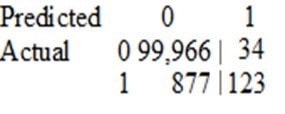
Which combination of steps should the Data Scientist take to reduce the number of false positive predictions by the model? (Choose two.)
A. Change the XGBoost eval_metric parameter to optimize based on rmse instead of error.
B. Increase the XGBoost scale_pos_weight parameter to adjust the balance of positive and negative weights.
C. Increase the XGBoost max_depth parameter because the model is currently underfitting the data.
D. Change the XGBoost evaljnetric parameter to optimize based on AUC instead of error.
E. Decrease the XGBoost max_depth parameter because the model is currently overfitting the data.
-
Question 387:
A web-based company wants to improve its conversion rate on its landing page. Using a large historical dataset of customer visits, the company has repeatedly trained a multi-class deep learning network algorithm on Amazon SageMaker.
However, there is an overfitting problem: training data shows 90% accuracy in predictions, while test data shows 70% accuracy only.
The company needs to boost the generalization of its model before deploying it into production to maximize conversions of visits to purchases.
Which action is recommended to provide the HIGHEST accuracy model for the company's test and validation data?
A. Increase the randomization of training data in the mini-batches used in training.
B. Allocate a higher proportion of the overall data to the training dataset
C. Apply L1 or L2 regularization and dropouts to the training.
D. Reduce the number of layers and units (or neurons) from the deep learning network.
Related Exams:
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01)ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00)ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01)AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01)BDS-C00
AWS Certified Big Data - Speciality (BDS-C00)CLF-C02
AWS Certified Cloud Practitioner (CLF-C02)DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01)DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01)DBS-C01
AWS Certified Database - Specialty (DBS-C01)DOP-C02
AWS Certified DevOps Engineer - Professional (DOP-C02)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MLS-C01 exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.