MLS-C01 Exam Details
-
Exam Code
:MLS-C01 -
Exam Name
:AWS Certified Machine Learning - Specialty (MLS-C01) -
Certification
:Amazon Certifications -
Vendor
:Amazon -
Total Questions
:396 Q&As -
Last Updated
:May 26, 2026
Amazon MLS-C01 Online Questions & Answers
-
Question 291:
A financial services company is building a robust serverless data lake on Amazon S3. The data lake should be flexible and meet the following requirements:
1.Support querying old and new data on Amazon S3 through Amazon Athena and Amazon Redshift Spectrum.
2.Support event-driven ETL pipelines.
3.Provide a quick and easy way to understand metadata. Which approach meets trfese requirements?
A. Use an AWS Glue crawler to crawl S3 data, an AWS Lambda function to trigger an AWS Glue ETL job, and an AWS Glue Data catalog to search and discover metadata.
B. Use an AWS Glue crawler to crawl S3 data, an AWS Lambda function to trigger an AWS Batch job, and an external Apache Hive metastore to search and discover metadata.
C. Use an AWS Glue crawler to crawl S3 data, an Amazon CloudWatch alarm to trigger an AWS Batch job, and an AWS Glue Data Catalog to search and discover metadata.
D. Use an AWS Glue crawler to crawl S3 data, an Amazon CloudWatch alarm to trigger an AWS Glue ETL job, and an external Apache Hive metastore to search and discover metadata. -
Question 292:
A Data Engineer needs to build a model using a dataset containing customer credit card information
How can the Data Engineer ensure the data remains encrypted and the credit card information is secure?
A. Use a custom encryption algorithm to encrypt the data and store the data on an Amazon SageMaker instance in a VPC. Use the SageMaker DeepAR algorithm to randomize the credit card numbers.
B. Use an IAM policy to encrypt the data on the Amazon S3 bucket and Amazon Kinesis to automatically discard credit card numbers and insert fake credit card numbers.
C. Use an Amazon SageMaker launch configuration to encrypt the data once it is copied to the SageMaker instance in a VPC. Use the SageMaker principal component analysis (PCA) algorithm to reduce the length of the credit card numbers.
D. Use AWS KMS to encrypt the data on Amazon S3 and Amazon SageMaker, and redact the credit card numbers from the customer data with AWS Glue. -
Question 293:
A city wants to monitor its air quality to address the consequences of air pollution A Machine Learning Specialist needs to forecast the air quality in parts per million of contaminates for the next 2 days in the city As this is a prototype, only daily data from the last year is available
Which model is MOST likely to provide the best results in Amazon SageMaker?
A. Use the Amazon SageMaker k-Nearest-Neighbors (kNN) algorithm on the single time series consisting of the full year of data with a predictor_type of regressor.
B. Use Amazon SageMaker Random Cut Forest (RCF) on the single time series consisting of the full year of data.
C. Use the Amazon SageMaker Linear Learner algorithm on the single time series consisting of the full year of data with a predictor_type of regressor.
D. Use the Amazon SageMaker Linear Learner algorithm on the single time series consisting of the full year of data with a predictor_type of classifier. -
Question 294:
A healthcare company wants to create a machine learning (ML) model to predict patient outcomes. A data science team developed an ML model by using a custom ML library. The company wants to use Amazon SageMaker to train this model. The data science team creates a custom SageMaker image to train the model. When the team tries to launch the custom image in SageMaker Studio, the data scientists encounter an error within the application.
Which service can the data scientists use to access the logs for this error?
A. Amazon S3
B. Amazon Elastic Block Store (Amazon EBS)
C. AWS CloudTrail
D. Amazon CloudWatch -
Question 295:
A data scientist needs to create a model for predictive maintenance. The model will be based on historical data to identify rare anomalies in the data.
The historical data is stored in an Amazon S3 bucket. The data scientist needs to use Amazon SageMaker Data Wrangler to ingest the data. The data scientists also needs to perform exploratory data analysis (EDA) to understand the statistical properties of the data.
Which solution will meet these requirements with the LEAST amount of compute resources?
A. Import the data by using the None option.
B. Import the data by using the Stratified option.
C. Import the data by using the First K option. Infer the value of K from domain knowledge.
D. Import the data by using the Randomized option. Infer the random size from domain knowledge. -
Question 296:
A media company wants to deploy a machine learning (ML) model that uses Amazon SageMaker to recommend new articles to the company's readers. The company's readers are primarily located in a single city.
The company notices that the heaviest reader traffic predictably occurs early in the morning, after lunch, and again after work hours. There is very little traffic at other times of day. The media company needs to minimize the time required to deliver recommendations to its readers. The expected amount of data that the API call will return for inference is less than 4 MB.
Which solution will meet these requirements in the MOST cost-effective way?
A. Real-time inference with auto scaling
B. Serverless inference with provisioned concurrency
C. Asynchronous inference
D. A batch transform task -
Question 297:
A retail company wants to create a system that can predict sales based on the price of an item. A machine learning (ML) engineer built an initial linear model that resulted in the following residual plot:
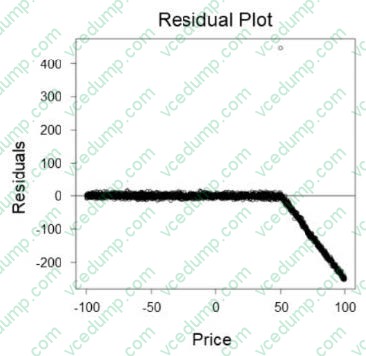
Which actions should the ML engineer take to improve the accuracy of the predictions in the next phase of model building? (Choose three.)
A. Downsample the data uniformly to reduce the amount of data.
B. Create two different models for different sections of the data.
C. Downsample the data in sections where Price < 50.
D. Offset the input data by a constant value where Price > 50.
E. Examine the input data, and apply non-linear data transformations where appropriate.
F. Use a non-linear model instead of a linear model. -
Question 298:
The displayed graph is from a forecasting model for testing a time series.
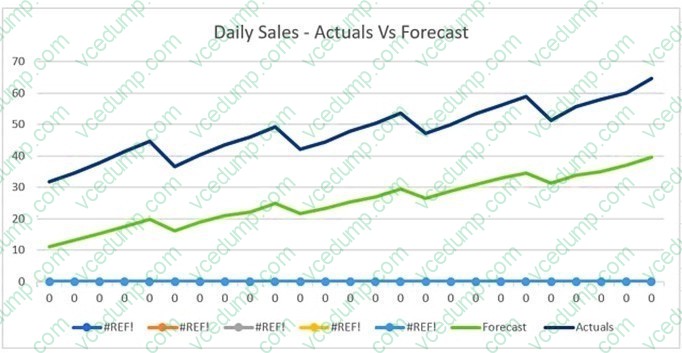
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
A. The model predicts both the trend and the seasonality well.
B. The model predicts the trend well, but not the seasonality.
C. The model predicts the seasonality well, but not the trend.
D. The model does not predict the trend or the seasonality well. -
Question 299:
A company wants to deliver digital car management services to its customers. The company plans to analyze data to predict the likelihood of users changing cars. The company has 10 TB of data that is stored in an Amazon Redshift cluster.
The company's data engineering team is using Amazon SageMaker Studio for data analysis and model development. Only a subset of the data is relevant for developing the machine learning models. The data engineering team needs a
secure and cost-effective way to export the data to a data repository in Amazon S3 for model development.
Which solutions will meet these requirements? (Choose two.)
A. Launch multiple medium-sized instances in a distributed SageMaker Processing job. Use the prebuilt Docker images for Apache Spark to query and plot the relevant data and to export the relevant data from Amazon Redshift to Amazon S3.
B. Launch multiple medium-sized notebook instances with a PySpark kernel in distributed mode. Download the data from Amazon Redshift to the notebook cluster. Query and plot the relevant data. Export the relevant data from the notebook cluster to Amazon S3.
C. Use AWS Secrets Manager to store the Amazon Redshift credentials. From a SageMaker Studio notebook, use the stored credentials to connect to Amazon Redshift with a Python adapter. Use the Python client to query the relevant data and to export the relevant data from Amazon Redshift to Amazon S3.
D. Use AWS Secrets Manager to store the Amazon Redshift credentials. Launch a SageMaker extra-large notebook instance with block storage that is slightly larger than 10 TB. Use the stored credentials to connect to Amazon Redshift with a Python adapter. Download, query, and plot the relevant data. Export the relevant data from the local notebook drive to Amazon S3.
E. Use SageMaker Data Wrangler to query and plot the relevant data and to export the relevant data from Amazon Redshift to Amazon S3. -
Question 300:
A medical imaging company wants to train a computer vision model to detect areas of concern on patients' CT scans. The company has a large collection of unlabeled CT scans that are linked to each patient and stored in an Amazon S3 bucket. The scans must be accessible to authorized users only. A machine learning engineer needs to build a labeling pipeline.
Which set of steps should the engineer take to build the labeling pipeline with the LEAST effort?
A. Create a workforce with AWS Identity and Access Management (IAM). Build a labeling tool on Amazon EC2 Queue images for labeling by using Amazon Simple Queue Service (Amazon SQS). Write the labeling instructions.
B. Create an Amazon Mechanical Turk workforce and manifest file. Create a labeling job by using the built-in image classification task type in Amazon SageMaker Ground Truth. Write the labeling instructions.
C. Create a private workforce and manifest file. Create a labeling job by using the built-in bounding box task type in Amazon SageMaker Ground Truth. Write the labeling instructions.
D. Create a workforce with Amazon Cognito. Build a labeling web application with AWS Amplify. Build a labeling workflow backend using AWS Lambda. Write the labeling instructions.
Related Exams:
-
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01) -
AIP-C01
AWS Certified Generative AI Developer - Professional -
ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00) -
ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01) -
AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01) -
BDS-C00
AWS Certified Big Data - Speciality (BDS-C00) -
CLF-C02
AWS Certified Cloud Practitioner (CLF-C02) -
DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01) -
DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01) -
DBS-C01
AWS Certified Database - Specialty (DBS-C01)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MLS-C01 exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.