MULESOFT-INTEGRATION-ARCHITECT-I Exam Details
-
Exam Code
:MULESOFT-INTEGRATION-ARCHITECT-I -
Exam Name
:Salesforce Certified MuleSoft Platform Integration Architect (Mule-Arch-202) -
Certification
:Salesforce Certifications -
Vendor
:Salesforce -
Total Questions
:273 Q&As -
Last Updated
:May 29, 2026
Salesforce MULESOFT-INTEGRATION-ARCHITECT-I Online Questions & Answers
-
Question 81:
A Mule application is being designed to do the following:
Step 1: Read a SalesOrder message from a JMS queue, where each SalesOrder consists of a header and a list of SalesOrderLineltems.
Step 2: Insert the SalesOrder header and each SalesOrderLineltem into different tables in an RDBMS.
Step 3: Insert the SalesOrder header and the sum of the prices of all its SalesOrderLineltems into a table In a different RDBMS.
No SalesOrder message can be lost and the consistency of all SalesOrder-related information in both RDBMSs must be ensured at all times.
What design choice (including choice of transactions) and order of steps addresses these requirements?
A. 1) Read the JMS message (NOT in an XA transaction) 2) Perform BOTH DB inserts in ONE DB transaction 3) Acknowledge the JMS message
B. 1) Read the JMS message (NOT in an XA transaction) 2) Perform EACH DB insert in a SEPARATE DB transaction 3) Acknowledge the JMS message
C. 1) Read the JMS message in an XA transaction 2) In the SAME XA transaction, perform BOTH DB inserts but do NOT acknowledge the JMS message
D. 1) Read and acknowledge the JMS message (NOT in an XA transaction) 2) In a NEW XA transaction, perform BOTH DB inserts -
Question 82:
In a Mule Application, a flow contains two (2) JMS consume operations that are used to connect to a JMS broker and consume messages from two(2) JMS destination. The Mule application then joins the two JMS messages together.
The JMS broker does not implement high availability (HA) and periodically experiences scheduled outages of upto 10 mins for routine maintenance.
What is the most idiomatic (used for its intented purpose) way to build the mule flow so it can best recover from the expected outages?
A. Configure a reconnection strategy for the JMS connector
B. Enclose the two(2) JMS operation in an Until Successful scope
C. Consider a transaction for the JMS connector
D. Enclose the two(2) JMS operations in a Try scope with an Error Continue error handler -
Question 83:
An API client makes an HTTP request to an API gateway with an Accept header containing the value'' application''.
What is a valid HTTP response payload for this request in the client requested data format?
A. healthy
B. {"status" "healthy"}
C. status(`healthy")
D. status: healthy -
Question 84:
A mule application uses an HTTP request operation to involve an external API.
The external API follows the HTTP specification for proper status code usage.
What is possible cause when a 3xx status code is returned to the HTTP Request operation from the external API?
A. The request was not accepted by the external API
B. The request was Redirected to a different URL by the external API
C. The request was NOT RECEIVED by the external API
D. The request was ACCEPTED by the external API -
Question 85:
Why would an Enterprise Architect use a single enterprise-wide canonical data model (CDM) when designing an integration solution using Anypoint Platform?
A. To reduce dependencies when integrating multiple systems that use different data formats
B. To automate Al-enabled API implementation generation based on normalized backend databases from separate vendors
C. To leverage a data abstraction layer that shields existing Mule applications from nonbackward compatible changes to the model's data structure
D. To remove the need to perform data transformation when processing message payloads in Mule applications -
Question 86:
An organization is designing a Mule application to periodically poll an SFTP location for new files containing sales order records and then process those sales orders. Each sales order must be processed exactly once.
To support this requirement, the Mule application must identify and filter duplicate sales orders on the basis of a unique ID contained in each sales order record and then only send the new sales orders to the downstream system.
What is the most idiomatic (used for its intended purpose) Anypoint connector, validator, or scope that can be configured in the Mule application to filter duplicate sales orders on the basis of the unique ID field contained in each sales order record?
A. Configure a Cache scope to filter and store each record from the received file by the order ID
B. Configure a Database connector to filter and store each record by the order ID
C. Configure an Idempotent Message Validator component to filter each record by the order ID
D. Configure a watermark In an On New or Updated File event source to filter unique records by the order ID -
Question 87:
Refer to the exhibit.
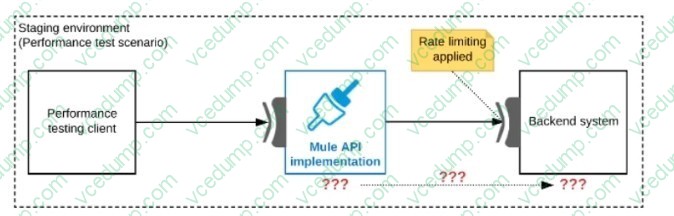
One of the backend systems invoked by an API implementation enforces rate limits on the number of requests a particular client can make. Both the backend system and the API implementation are deployed to several non-production environments in addition to production.
Rate limiting of the backend system applies to all non-production environments. The production environment, however, does NOT have any rate limiting.
What is the most effective approach to conduct performance tests of the API implementation in a staging (non-production) environment?
A. Create a mocking service that replicates the backend system's production performance characteristics. Then configure the API implementation to use the mocking service and conduct the performance tests
B. Use MUnit to simulate standard responses from the backend system then conduct performance tests to identify other bottlenecks in the system
C. Include logic within the API implementation that bypasses invocations of the backend system in a performance test situation. Instead invoking local stubs that replicate typical backend system responses then conduct performance tests using this API Implementation
D. Conduct scaled-down performance tests in the staging environment against the rate limited backend system then upscale performance results to full production scale -
Question 88:
An organization is designing multiple new applications to run on CloudHub in a single Anypoint VPC and that must share data using a common persistent Anypoint object store V2 (OSv2).
Which design gives these mule applications access to the same object store instance?
A. AVM connector configured to directly access the persistence queue of the persistent object store
B. An Anypoint MQ connector configured to directly access the persistent object store
C. Object store V2 can be shared across cloudhub applications with the configured osv2 connector
D. The object store V2 rest API configured to access the persistent object store -
Question 89:
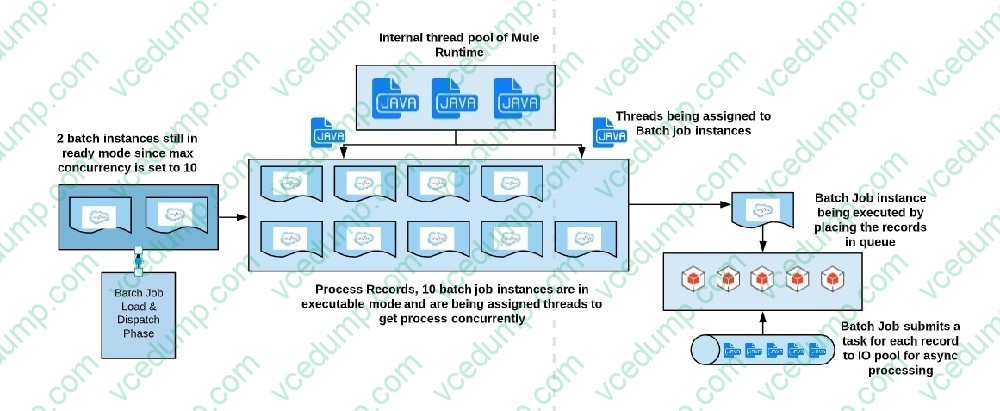
A Mule application contains a Batch Job with two Batch Steps (Batch_Step_l and Batch_Step_2). A payload with 1000 records is received by the Batch Job.
How many threads are used by the Batch Job to process records, and how does each Batch Step process records within the Batch Job?
A. Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and RECORDS are processed IN PARALLEL within and between the two Batch Steps
B. Each Batch Job uses a SINGLE THREAD for all Batch steps Each Batch step instance receives ONE record at a time as the payload, and RECORDS are processed IN ORDER, first through Batch_Step_l and then through Batch_Step_2
C. Each Batch Job uses a SINGLE THREAD to process a configured block size of record Each Batch Step instance receives A BLOCK OF records as the payload, and BLOCKS of records are processed IN ORDER
D. Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and BATCH STEP INSTANCES execute IN PARALLEL to process records and Batch Steps in ANY order as fast as possible -
Question 90:
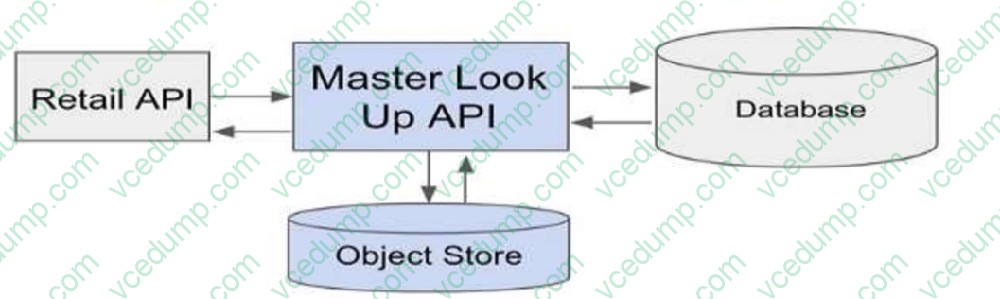
A manufacturing company is developing a new set of APIs for its retail business. One of the APIs is a Master Look Up API, which is a System API,
The API uses a persistent object-store. This API will be used by almost all other APIs to provide master lookup data.
The Master Look Up API is deployed on two CloudHub workers of 0.1 vCore each because there is a lot of master data to be cached. Most of the master lookup data is stored as a key-value pair. The cache gets refreshed if the key is not
found in the cache.
During performance testing, it was determined that the Master Look Up API has a high response time due to the latency of database queries executed to fetch the master lookup data.
What two methods can be used to resolve these performance issues?
Choose 2 answers
A. Implement the HTTP caching policy for all GET endpoints for the Master Look Up API
B. Implement an HTTP caching policy for all GET endpoints in the Master Look Up API
C. Implement locking to synchronize access to the Object Store
D. Upgrade the vCore size from 0.1 vCore to 0.2 vCore
Related Exams:
-
201-COMMERCIAL-BANKING-FUNCTIONAL
Salesforce enCino 201 Commercial Banking Functional -
ADM-201
Salesforce Certified Platform Administrator (Plat-Admn-201) -
ADM-211
Administration Essentials for Experienced Admin (ADM-211) -
ADM-261
Service Cloud Administration (SU24) -
ADVANCED-ADMINISTRATOR
Salesforce Certified Advanced Administrator -
ADVANCED-CROSS-CHANNEL
Marketing Cloud Advanced Cross Channel Accredited Professional -
ADX-201
Administrative Essentials for New Admins in Lightning Experience -
ADX-271
Salesforce Certified Community Cloud Consultant (ADX-271) -
AGENTFORCE-SPECIALIST
Salesforce Certified Agentforce Specialist (AI-201) -
ALS-CON-201
Salesforce Certified Agentforce Life Sciences Consultant
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Salesforce exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MULESOFT-INTEGRATION-ARCHITECT-I exam preparations and Salesforce certification application, do not hesitate to visit our Vcedump.com to find your solutions here.