DATABRICKS-MACHINE-LEARNING-ASSOCIATE Exam Details
-
Exam Code
:DATABRICKS-MACHINE-LEARNING-ASSOCIATE -
Exam Name
:Databricks Certified Machine Learning Associate -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:74 Q&As -
Last Updated
:Jul 14, 2026
Databricks DATABRICKS-MACHINE-LEARNING-ASSOCIATE Online Questions & Answers
-
Question 11:
A data scientist has produced two models for a single machine learning problem. One of the models performs well when one of the features has a value of less than 5, and the other model performs well when the value of that feature is greater than or equal to 5. The data scientist decides to combine the two models into a single machine learning solution.
Which of the following terms is used to describe this combination of models?
A. Bootstrap aggregation
B. Support vector machines
C. Bucketing
D. Ensemble learning
E. Stacking -
Question 12:
A data scientist is working with a feature set with the following schema:

Thecustomer_idcolumn is the primary key in the feature set. Each of the columns in the feature set has missing values. They want to replace the missing values by imputing a common value for each feature.
Which of the following lists all of the columns in the feature set that need to be imputed using the most common value of the column?
A. customer_id, loyalty_tier
B. loyalty_tier
C. units
D. spend
E. customer_id -
Question 13:
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.
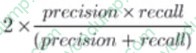
Which of the following suggestions should the team include in their guidelines?
A. The F1 score should be utilized over accuracy when the number of actual positive cases is identical to the number of actual negative cases.
B. The F1 score should be utilized over accuracy when there are greater than two classes in the target variable.
C. The F1 score should be utilized over accuracy when there is significant imbalance between positive and negative classes and avoiding false negatives is a priority.
D. The F1 score should be utilized over accuracy when identifying true positives and true negatives are equally important to the business problem. -
Question 14:
A data scientist has created two linear regression models. The first model uses price as a label variable and the second model uses log(price) as a label variable. When evaluating the RMSE of each model bycomparing the label predictions to the actual price values, the data scientist notices that the RMSE for the second model is much larger than the RMSE of the first model.
Which of the following possible explanations for this difference is invalid?
A. The second model is much more accurate than the first model
B. The data scientist failed to exponentiate the predictions in the second model prior tocomputingthe RMSE
C. The datascientist failed to take the logof the predictions in the first model prior to computingthe RMSE
D. The first model is much more accurate than the second model
E. The RMSE is an invalid evaluation metric for regression problems -
Question 15:
A data scientist has a Spark DataFrame spark_df. They want to create a new Spark DataFrame that contains only the rows from spark_df where the value in column discount is less than or equal 0.
Which of the following code blocks will accomplish this task?
A. spark_df.loc[:,spark_df["discount"]
B. spark_df[spark_df["discount"]
C. spark_df.filter (col("discount")
D. spark_df.loc(spark_df["discount"] -
Question 16:
The implementation of linear regression in Spark ML first attempts to solve the linear regression problem using matrix decomposition, but this method does not scale well to large datasets with a large number of variables.
Which of the following approaches does Spark ML use to distribute the training of a linear regression model for large data?
A. Logistic regression
B. Singular value decomposition
C. Iterative optimization
D. Least-squares method -
Question 17:
Which of the following machine learning algorithms typically uses bagging?
A. IGradient boosted trees
B. K-means
C. Random forest
D. Decision tree -
Question 18:
A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
A. Option A
B. Option B
C. Option C
D. Option D -
Question 19:
A data scientist is attempting to tune a logistic regression model logistic using scikit-learn. They want to specify a search space for two hyperparameters and let the tuning process randomly select values for each evaluation.
They attempt to run the following code block, but it does not accomplish the desired task:

Which of the following changes can the data scientist make to accomplish the task?
A. Replace the GridSearchCV operation with RandomizedSearchCV
B. Replace the GridSearchCV operation with cross_validate
C. Replace the GridSearchCV operation with ParameterGrid
D. Replace the random_state=0 argument with random_state=1
E. Replace the penalty= ['12', '11'] argument with penalty=uniform ('12', '11') -
Question 20:
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
A. import pyspark.pandas as ps df = ps.DataFrame(spark_df)
B. import pyspark.pandas as ps df = ps.to_pandas(spark_df)
C. spark_df.to_sql()
D. import pandas as pd df = pd.DataFrame(spark_df)
E. spark_df.to_pandas()
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-MACHINE-LEARNING-ASSOCIATE exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.