DP-100 Exam Details
-
Exam Code
:DP-100 -
Exam Name
:Designing and Implementing a Data Science Solution on Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:617 Q&As -
Last Updated
:Jul 17, 2026
Microsoft DP-100 Online Questions & Answers
-
Question 471:
You use the Azure Machine Learning service to create a tabular dataset named training_data. You plan to use this dataset in a training script.
You create a variable that references the dataset using the following code:
training_ds = workspace.datasets.get("training_data")
You define an estimator to run the script.
You need to set the correct property of the estimator to ensure that your script can access the training_data dataset.
Which property should you set?
A. environment_definition = {"training_data":training_ds}
B. inputs = [training_ds.as_named_input('training_ds')]
C. script_params = {"--training_ds":training_ds}
D. source_directory = training_ds -
Question 472:
DRAG DROP
You have an Azure Machine Learning workspace named WS1 and a GitHub account named account1 that hosts a private repository named repo1.
You need to clone repo1 to make it available directly from WS1. The configuration must maximize the performance of the repo1 clone.
Which four actions should you perform in sequence?
Select and Place:

-
Question 473:
You manage an Azure Machine Learning workspace.
You choose the uri_folder data type as an output of a pipeline component.
You need to define the data access mode that is supported by your configuration.
Which mode should you define?
A. eval_upload
B. rw_mount
C. download
D. ro_mount -
Question 474:
You use the Azure Machine Learning SDK to run a training experiment that trains a classification model and calculates its accuracy metric.
The model will be retrained each month as new data is available.
You must register the model for use in a batch inference pipeline.
You need to register the model and ensure that the models created by subsequent retraining experiments are registered only if their accuracy is higher than the currently registered model.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Specify a different name for the model each time you register it.
B. Register the model with the same name each time regardless of accuracy, and always use the latest version of the model in the batch inferencing pipeline.
C. Specify the model framework version when registering the model, and only register subsequent models if this value is higher.
D. Specify a property named accuracy with the accuracy metric as a value when registering the model, and only register subsequent models if their accuracy is higher than the accuracy property value of the currently registered model.
E. Specify a tag named accuracy with the accuracy metric as a value when registering the model, and only register subsequent models if their accuracy is higher than the accuracy tag value of the currently registered model. -
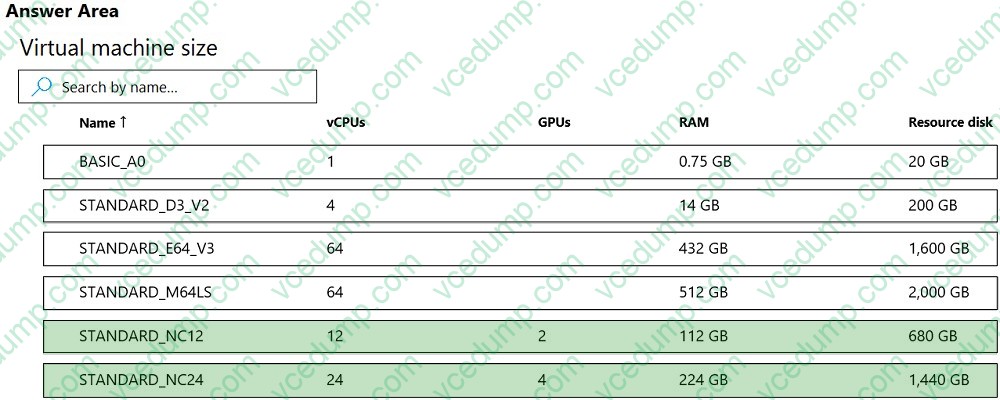
Question 475:
HOTSPOT
You are developing a deep learning model by using TensorFlow. You plan to run the model training workload on an Azure Machine Learning Compute Instance.
You must use CUDA-based model training.
You need to provision the Compute Instance.
Which two virtual machines sizes can you use? To answer, select the appropriate virtual machine sizes in the answer area.
NOTE: Each correct selection is worth one point.
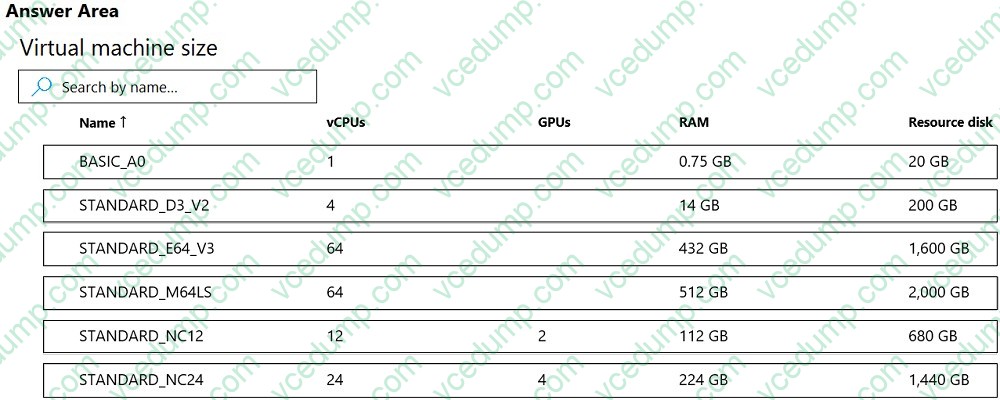
-
Question 476:
You plan to use a Deep Learning Virtual Machine (DLVM) to train deep learning models using Compute Unified Device Architecture (CUDA) computations.
You need to configure the DLVM to support CUDA.
What should you implement?
A. Solid State Drives (SSD)
B. Computer Processing Unit (CPU) speed increase by using overclocking
C. Graphic Processing Unit (GPU)
D. High Random Access Memory (RAM) configuration
E. Intel Software Guard Extensions (Intel SGX) technology -
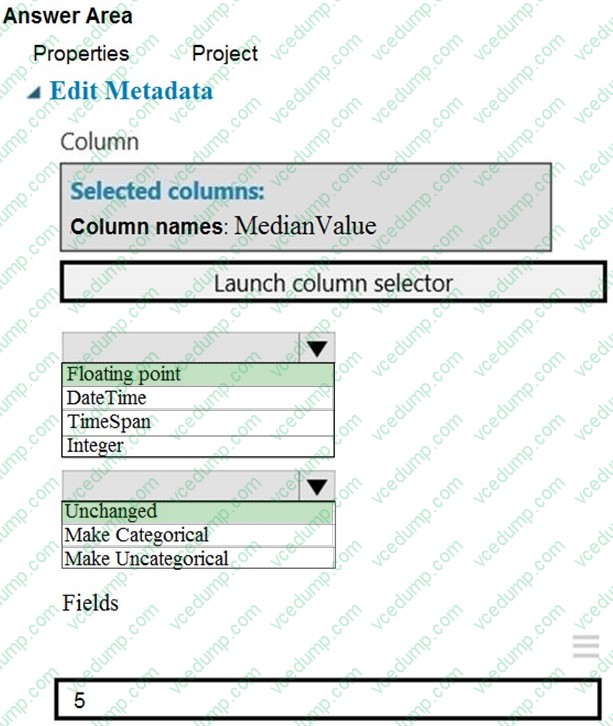
Question 477:
HOTSPOT
You need to configure the Edit Metadata module so that the structure of the datasets match.
Which configuration options should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
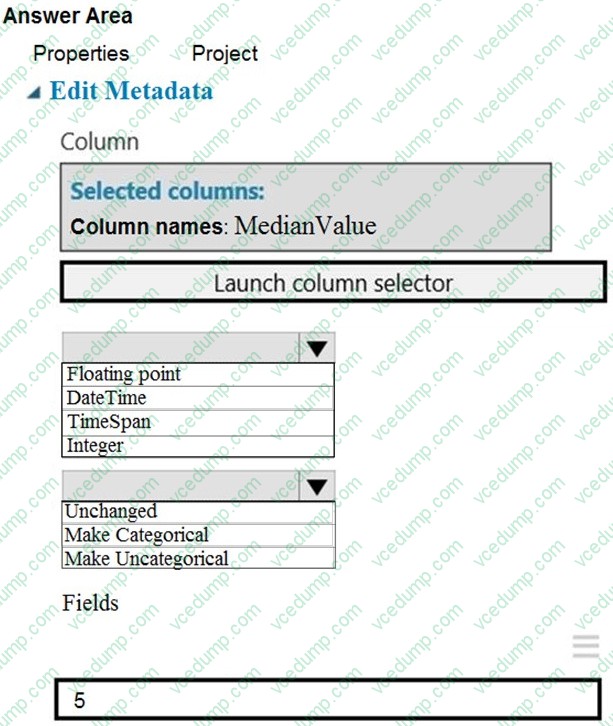
-
Question 478:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train a classification model by using a logistic regression algorithm.
You must be able to explain the model's predictions by calculating the importance of each feature, both as an overall global relative importance value and as a measure of local importance for a specific set of predictions.
You need to create an explainer that you can use to retrieve the required global and local feature importance values.
Solution: Create a MimicExplainer.
Does the solution meet the goal?
A. Yes
B. No -
Question 479:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder.
You must run the script as an Azure ML experiment on a compute cluster named aml-compute.
You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml-compute that references the target compute cluster.
Solution: Run the following code:

Does the solution meet the goal?
A. Yes
B. No -
Question 480:
DRAG DROP
You build a binary classification model using the Azure Machine Learning Studio Two-Class Neural Network module.
You are preparing to configure the Tune Model Hyperparameters module for the purpose of tuning accuracy for the model.
Which of the following are valid parameters for the Two-Class Neural Network module? Answer by dragging the correct options from the list to the answer area.
Select and Place:



Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.