DP-100 Exam Details
-
Exam Code
:DP-100 -
Exam Name
:Designing and Implementing a Data Science Solution on Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:617 Q&As -
Last Updated
:Jul 17, 2026
Microsoft DP-100 Online Questions & Answers
-
Question 461:
You have a Jupyter Notebook that contains Python code that is used to train a model.
You must create a Python script for the production deployment. The solution must minimize code maintenance.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Refactor the Jupyter Notebook code into functions
B. Save each function to a separate Python file
C. Define a main() function in the Python script
D. Remove all comments and functions from the Python script -
Question 462:
You are in the process of creating a machine learning model. Your dataset includes rows with null and missing values.
You plan to make use of the Clean Missing Data module in Azure Machine Learning Studio to detect and fix the null and missing values in the dataset.
Recommendation: You make use of the Custom substitution value option.
Will the requirements be satisfied?
A. Yes
B. No -
Question 463:
DRAG DROP
You provision an Azure Machine Learning workspace in a new Azure subscription.
You need to attach Azure Databricks as a compute resource from the Azure Machine Learning workspace.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

-
Question 464:
You manage an Azure Machine Learning workspace by using the Azure CLI ml extension v2.
You need to define a YAML schema to create a compute cluster.
Which schema should you use?
A. https://azuremlschemas.azureedge.net/latest/computdnstarKeichema.json
B. https://azuremlschemas.azureedge.net/latest/amlCompute.schemajson
C. https://azuremlschemas.azureedge.net/latest/vmCompute.schema.json
D. https://azuremlschemas.azureedge.net/latest/kubernetesCompute.schema.json -
Question 465:
HOTSPOT
You are using the Azure Machine Learning designer to transform a dataset containing the census data of all nations.
You must use the Split Data component to separate the dataset into two datasets. The first dataset must contain the census data of the United States. The second dataset must include the census data of the remaining nations.
You need to configure the component to create the datasets.
Which configuration values should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

-
Question 466:
You need to implement a new cost factor scenario for the ad response models as illustrated in the performance curve exhibit.
Which technique should you use?
A. Set the threshold to 0.5 and retrain if weighted Kappa deviates +/- 5% from 0.45.
B. Set the threshold to 0.05 and retrain if weighted Kappa deviates +/- 5% from 0.5.
C. Set the threshold to 0.2 and retrain if weighted Kappa deviates +/- 5% from 0.6.
D. Set the threshold to 0.75 and retrain if weighted Kappa deviates +/- 5% from 0.15. -
Question 467:
You train and publish a machine learning model.
You need to run a pipeline that retrains the model based on a trigger from an external system.
What should you configure?
A. Azure Data Catalog
B. Azure Batch
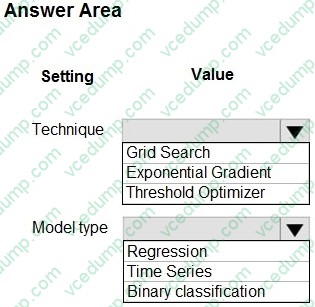
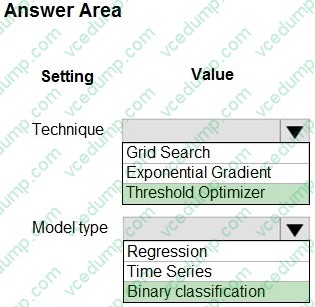
C. Azure Logic App -
Question 468:
HOTSPOT
You have machine learning models produce unfair predictions across sensitive features.
You must use a post-processing technique to apply a constraint to the models to mitigate their unfairness.
You need to select a post-processing technique and model type.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
-
Question 469:
You are creating a new Azure Machine Learning pipeline using the designer.
The pipeline must train a model using data in a comma-separated values (CSV) file that is published on a website. You have not created a dataset for this file.
You need to ingest the data from the CSV file into the designer pipeline using the minimal administrative effort.
Which module should you add to the pipeline in Designer?
A. Convert to CSV
B. Enter Data Manually
C. Import Data
D. Dataset -
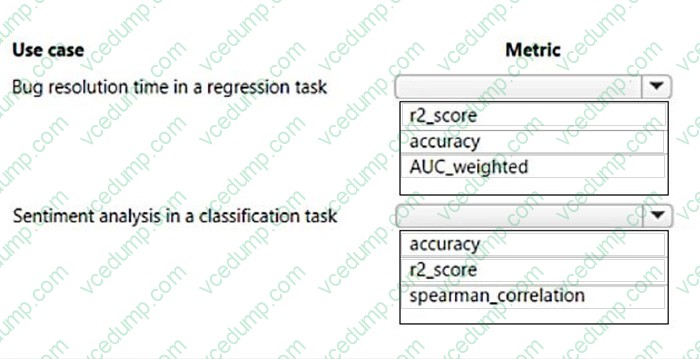
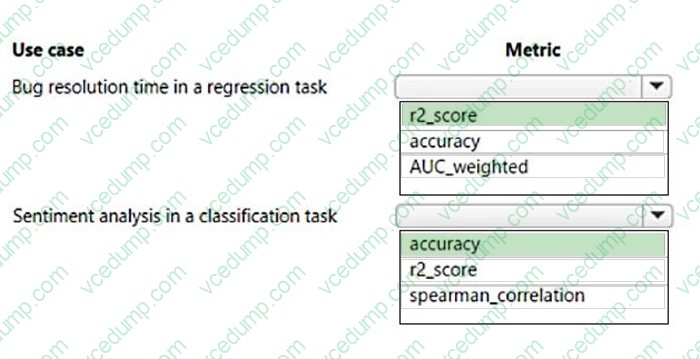
Question 470:
HOTSPOT
You create multiple machine learning models by using automated machine learning.
You need to configure a primary metric for each use case.
Which metrics should you configure? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.