DP-100 Exam Details
-
Exam Code
:DP-100 -
Exam Name
:Designing and Implementing a Data Science Solution on Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:617 Q&As -
Last Updated
:Jul 17, 2026
Microsoft DP-100 Online Questions & Answers
-
Question 271:
DRAG DROP
You design a project for interactive data wrangling with Apache Spark in an Azure Machine Learning workspace.
The data pipeline must provide the following:
1. Ingest and process a large amount of data from various sources and linked services, such as databases and APIs
2. Visualize the results in Microsoft Power BI
3. Quickly identify and address issues by observing a small amount of data using the fewest resources
You need to select a compute option for project activities.
Select and Place:

-
Question 272:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Replace each missing value using the Multiple Imputation by Chained Equations (MICE) method.
Does the solution meet the goal?
A. Yes
B. No -
Question 273:
HOTSPOT
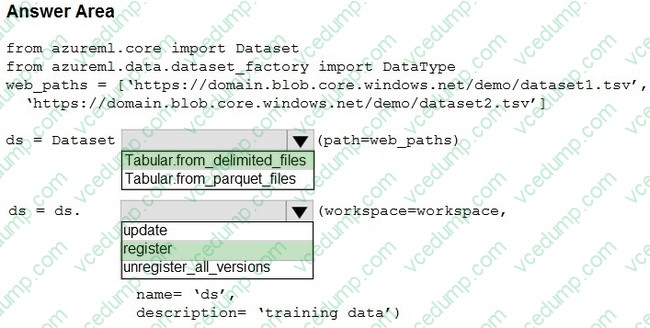
You create an Azure Machine Learning workspace. You use the Azure Machine Learning SDK for Python.
You must create a dataset from remote paths. The dataset must be reusable within the workspace.
You need to create the dataset.
How should you complete the following code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
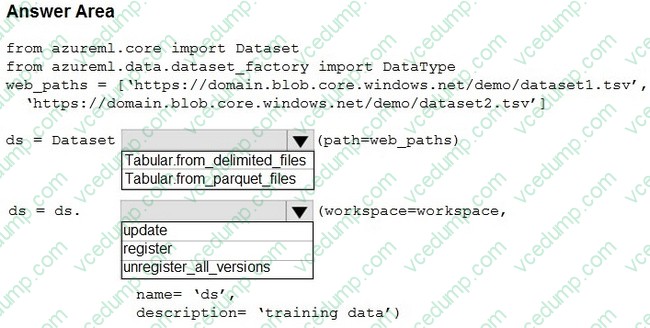
-
Question 274:
You manage an Azure Machine Learning workspace.
You must provide explanations for the behavior of the models with feature importance measures.
You need to configure a Responsible AI dashboard in Azure Machine Learning.
Which dashboard component should you configure?
A. Counterfactual what-if
B. Casual inference
C. Fairness assessment
D. Interpretability -
Question 275:
You manage an Azure Machine Learning Workspace named Workspase1 and an Azure Files share named Share1.
You plan to create an Azure Files datastore in Workspace1 to target Share1.
You need to configure permanent access to Share1 from the Azure Files datastore.
Which authorization method should you use?
A. Secondary access key
B. Anonymous access
C. Account SAS key
D. Service SAS key -
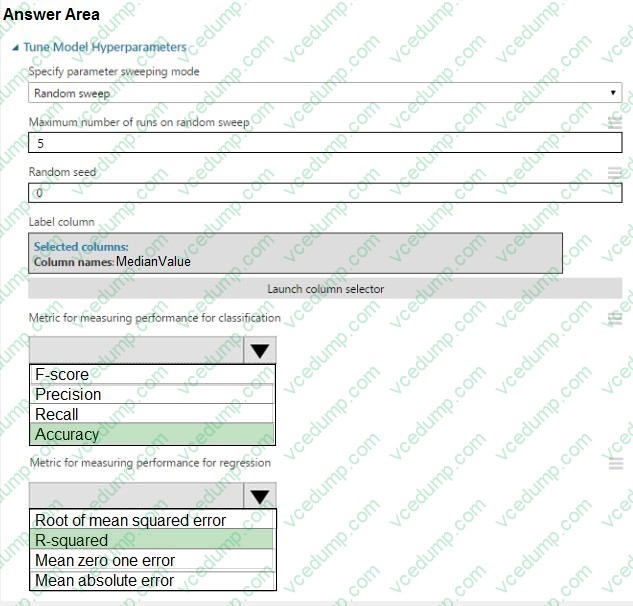
Question 276:
HOTSPOT
You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
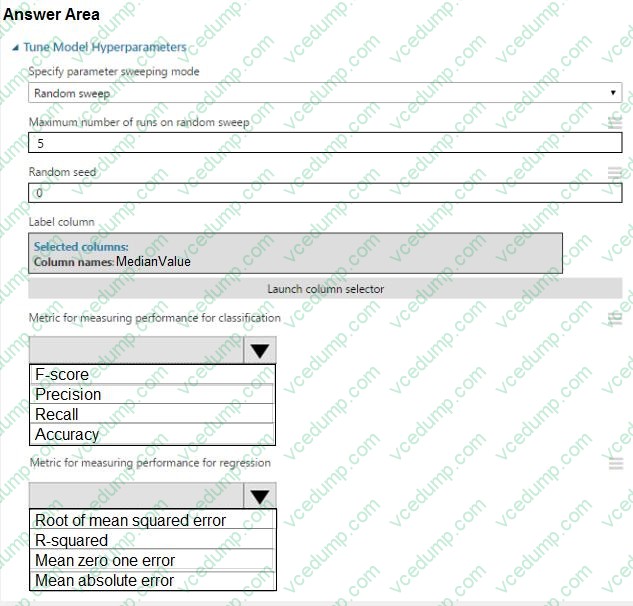
-
Question 277:
You manage an Azure Machine Learning workspace.
You build a custom model you must log with MLflow. The custom model includes the following:
The model is not natively supported by MLflow.
The model cannot be serialized in Pickle format.
The model source code is complex.
The Python library for the model must be packaged with the model.
You need to create a custom model flavor to enable logging with MLflow.
What should you use?
A. model loader
B. artifacts
C. model wrapper
D. custom signatures -
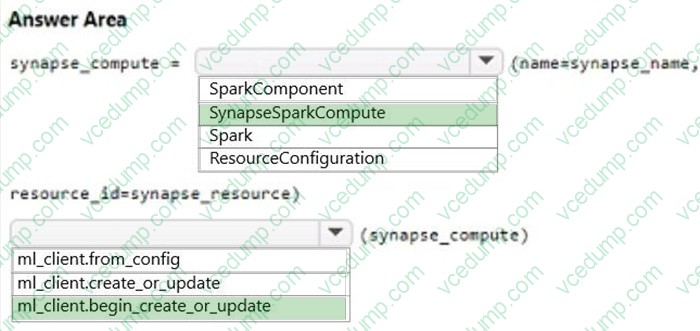
Question 278:
HOTSPOT
You are creating data wrangling and model training solutions in an Azure Machine Learning workspace.
You must use the same Python notebook to perform both data wrangling and model training.
You need to use the Azure Machine Learning Python SDK v2 to define and configure the Synapse Spark pool asynchronously in the workspace as dedicated compute.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
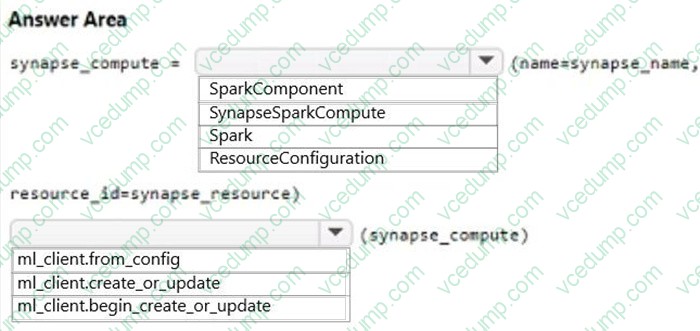
-
Question 279:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than the other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Scale and Reduce sampling mode.
Does the solution meet the goal?
A. Yes
B. No -
Question 280:
You are creating a classification model for a banking company to identify possible instances of credit card fraud. You plan to create the model in Azure Machine Learning by using automated machine learning.
The training dataset that you are using is highly unbalanced.
You need to evaluate the classification model.
Which primary metric should you use?
A. normalized_mean_absolute_error
B. AUC_weighted
C. accuracy
D. normalized_root_mean_squared_error
E. spearman_correlation

Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.