MLS-C01 Exam Details
-
Exam Code
:MLS-C01 -
Exam Name
:AWS Certified Machine Learning - Specialty (MLS-C01) -
Certification
:Amazon Certifications -
Vendor
:Amazon -
Total Questions
:396 Q&As -
Last Updated
:May 26, 2026
Amazon MLS-C01 Online Questions & Answers
-
Question 121:
A Machine Learning Specialist is assigned a TensorFlow project using Amazon SageMaker for training, and needs to continue working for an extended period with no Wi-Fi access. Which approach should the Specialist use to continue working?
A. Install Python 3 and boto3 on their laptop and continue the code development using that environment.
B. Download the TensorFlow Docker container used in Amazon SageMaker from GitHub to their local environment, and use the Amazon SageMaker Python SDK to test the code.
C. Download TensorFlow from tensorflow.org to emulate the TensorFlow kernel in the SageMaker environment.
D. Download the SageMaker notebook to their local environment then install Jupyter Notebooks on their laptop and continue the development in a local notebook. -
Question 122:
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class distribution for these features is illustrated in the figure provided.
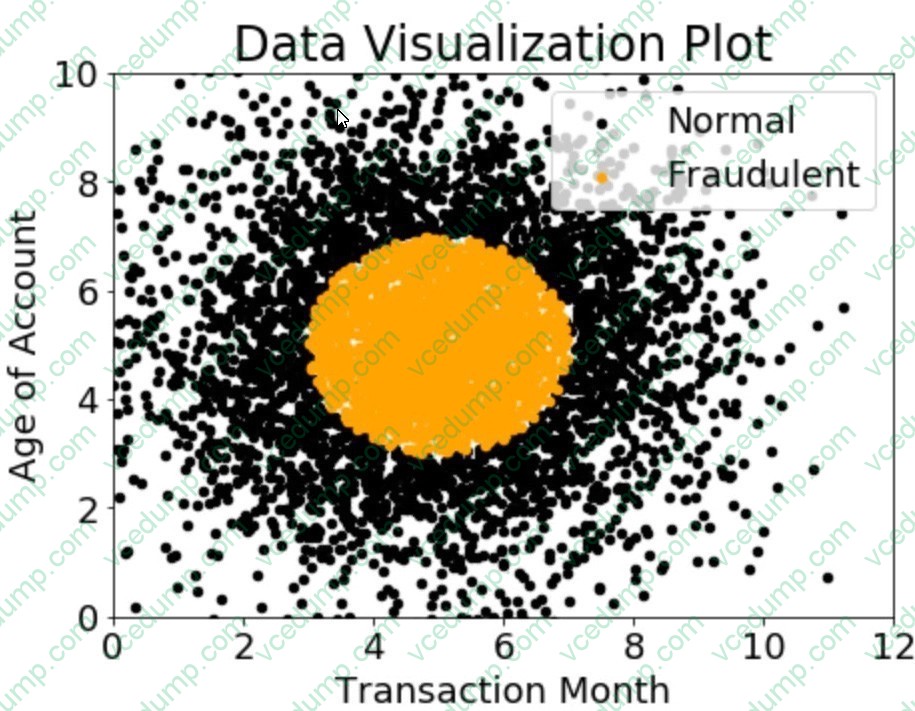
Based on this information, which model would have the HIGHEST recall with respect to the fraudulent class?
A. Decision tree
B. Linear support vector machine (SVM)
C. Naive Bayesian classifier
D. Single Perceptron with sigmoidal activation function -
Question 123:
A Machine Learning Specialist is packaging a custom ResNet model into a Docker container so the company can leverage Amazon SageMaker for training The Specialist is using Amazon EC2 P3 instances to train the model and needs to properly configure the Docker container to leverage the NVIDIA GPUs
What does the Specialist need to do1?
A. Bundle the NVIDIA drivers with the Docker image
B. Build the Docker container to be NVIDIA-Docker compatible
C. Organize the Docker container's file structure to execute on GPU instances.
D. Set the GPU flag in the Amazon SageMaker Create TrainingJob request body -
Question 124:
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a machine learning specialist will build a binary classifier based on two features: age of account, denoted by x, and transaction month, denoted by y. The class distributions are illustrated in the provided figure. The positive class is portrayed in red, while the negative class is portrayed in black.
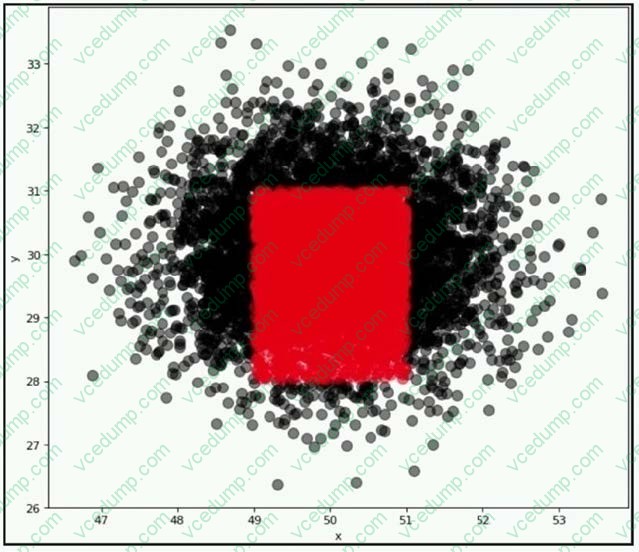
Which model would have the HIGHEST accuracy?
A. Linear support vector machine (SVM)
B. Decision tree
C. Support vector machine (SVM) with a radial basis function kernel
D. Single perceptron with a Tanh activation function -
Question 125:
A company that operates oil platforms uses drones to photograph locations on oil platforms that are difficult for humans to access to search for corrosion.
Experienced engineers review the photos to determine the severity of corrosion. There can be several corroded areas in a single photo. The engineers determine whether the identified corrosion needs to be fixed immediately, scheduled for
future maintenance, or requires no action. The corrosion appears in an average of 0.1% of all photos.
A data science team needs to create a solution that automates the process of reviewing the photos and classifying the need for maintenance.
Which combination of steps will meet these requirements? (Choose three.)
A. Use an object detection algorithm to train a model to identify corrosion areas of a photo.
B. Use Amazon Rekognition with label detection on the photos.
C. Use a k-means clustering algorithm to train a model to classify the severity of corrosion in a photo.
D. Use an XGBoost algorithm to train a model to classify the severity of corrosion in a photo.
E. Perform image augmentation on photos that contain corrosion.
F. Perform image augmentation on photos that do not contain corrosion. -
Question 126:
A data scientist is trying to improve the accuracy of a neural network classification model. The data scientist wants to run a large hyperparameter tuning job in Amazon SageMaker. However, previous smaller tuning jobs on the same model often ran for several weeks. The ML specialist wants to reduce the computation time required to run the tuning job.
Which actions will MOST reduce the computation time for the hyperparameter tuning job? (Choose two.)
A. Use the Hyperband tuning strategy.
B. Increase the number of hyperparameters.
C. Set a lower value for the MaxNumberOfTrainingJobs parameter.
D. Use the grid search tuning strategy.
E. Set a lower value for the MaxParallelTrainingJobs parameter. -
Question 127:
An e-commerce company needs a customized training model to classify images of its shirts and pants products The company needs a proof of concept in 2 to 3 days with good accuracy Which compute choice should the Machine Learning Specialist select to train and achieve good accuracy on the model quickly?
A. . m5 4xlarge (general purpose)
B. r5.2xlarge (memory optimized)
C. p3.2xlarge (GPU accelerated computing)
D. p3 8xlarge (GPU accelerated computing) -
Question 128:
A global financial company is using machine learning to automate its loan approval process. The company has a dataset of customer information. The dataset contains some categorical fields, such as customer location by city and housing status. The dataset also includes financial fields in different units, such as account balances in US dollars and monthly interest in US cents.
The company's data scientists are using a gradient boosting regression model to infer the credit score for each customer. The model has a training accuracy of 99% and a testing accuracy of 75%. The data scientists want to improve the model's testing accuracy.
Which process will improve the testing accuracy the MOST?
A. Use a one-hot encoder for the categorical fields in the dataset. Perform standardization on the financial fields in the dataset. Apply L1 regularization to the data.
B. Use tokenization of the categorical fields in the dataset. Perform binning on the financial fields in the dataset. Remove the outliers in the data by using the z-score.
C. Use a label encoder for the categorical fields in the dataset. Perform L1 regularization on the financial fields in the dataset. Apply L2 regularization to the data.
D. Use a logarithm transformation on the categorical fields in the dataset. Perform binning on the financial fields in the dataset. Use imputation to populate missing values in the dataset. -
Question 129:
A Machine Learning Specialist is working for an online retailer that wants to run analytics on every customer visit, processed through a machine learning pipeline. The data needs to be ingested by Amazon Kinesis Data Streams at up to 100 transactions per second, and the JSON data blob is 100 KB in size.
What is the MINIMUM number of shards in Kinesis Data Streams the Specialist should use to successfully ingest this data?
A. 1 shards
B. 10 shards
C. 100 shards
D. 1,000 shards -
Question 130:
An online retail company wants to develop a natural language processing (NLP) model to improve customer service. A machine learning (ML) specialist is setting up distributed training of a Bidirectional Encoder Representations from
Transformers (BERT) model on Amazon SageMaker. SageMaker will use eight compute instances for the distributed training.
The ML specialist wants to ensure the security of the data during the distributed training. The data is stored in an Amazon S3 bucket.
Which combination of steps should the ML specialist take to protect the data during the distributed training? (Choose three.)
A. Run distributed training jobs in a private VPC. Enable inter-container traffic encryption.
B. Run distributed training jobs across multiple VPCs. Enable VPC peering.
C. Create an S3 VPC endpoint. Then configure network routes, endpoint policies, and S3 bucket policies.
D. Grant read-only access to SageMaker resources by using an IAM role.
E. Create a NAT gateway. Assign an Elastic IP address for the NAT gateway.
F. Configure an inbound rule to allow traffic from a security group that is associated with the training instances.
Related Exams:
-
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01) -
AIP-C01
AWS Certified Generative AI Developer - Professional -
ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00) -
ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01) -
AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01) -
BDS-C00
AWS Certified Big Data - Speciality (BDS-C00) -
CLF-C02
AWS Certified Cloud Practitioner (CLF-C02) -
DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01) -
DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01) -
DBS-C01
AWS Certified Database - Specialty (DBS-C01)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your MLS-C01 exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.