Microsoft DP-203 Online Practice
Questions and Exam Preparation
DP-203 Exam Details
Exam Code
:DP-203
Exam Name
:Data Engineering on Microsoft Azure
Certification
:Microsoft Certifications
Vendor
:Microsoft
Total Questions
:422 Q&As
Last Updated
:Oct 02, 2025
Microsoft DP-203 Online Questions &
Answers
Question 21:
You have an Azure subscription that contains a storage account named storage1 and an Azure Synapse Analytics dedicated SQL pool. The storage1 account contains a CSV file that requires an account key for access.
You plan to read the contents of the CSV file by using an external table.
You need to create an external data source for the external table.
What should you create first?
A. a database role
B. a database scoped credential
C. a database view
D. an external file format
Correct Answer: B
External Data Source The external data source object provides the connection information required to connect to the external data source itself. Let's begin by collecting the URL and the access key. Sign in to the Azure Portal, and navigate to your storage account. Click on Access Keys and copy the Key and the Storage account name to a notepad.
Create an import database The next step is to create a database scoped credential to secure the credentials to the ADLS account. Create a database master key if one does not already exist, and then encrypt the database-scoped credential named ADLS_Credential using the master key.
You have an Azure Synapse Analytics workspace that contains an Apache Spark pool named SparkPool1. SparkPool1 contains a Delta Lake table named SparkTable1.
You need to recommend a solution that supports Transact-SQL queries against the data referenced by SparkTable1. The solution must ensure that the queries can use partition elimination.
What should you include in the recommendation?
A. a partitioned table in a dedicated SQL pool
B. a partitioned view in a dedicated SQL pool
C. a partitioned index in a dedicated SQL pool
D. a partitioned view in a serverless SQL pool
Correct Answer:
Explanation:
Delta Lake
There are some limitations that you might see in Delta Lake support in serverless SQL pools:
*
External tables don't support partitioning. Use partitioned views on the Delta Lake folder to use the partition elimination.
*
Etc.
Note: Partitioned views
If you have a set of files that is partitioned in the hierarchical folder structure, you can describe the partition pattern using the wildcards in the file path.
Partitioned views can improve the performance of your queries by performing partition elimination when you query them with filters on the partitioning columns. However, not all queries support partition elimination, so it's important to follow
some best practices.
Delta Lake partitioned views
If you are creating the partitioned views on top of Delta Lake storage, you can specify just a root Delta Lake folder and don't need to explicitly expose the partitioning columns using the FILEPATH function.
You have an Azure Databricks workspace and an Azure Data Lake Storage Gen2 account named storage1.
New files are uploaded daily to storage1.
You need to recommend a solution that configures storage1 as a structured streaming source. The solution must meet the following requirements:
1.
Incrementally process new files as they are uploaded to storage1.
2.
Minimize implementation and maintenance effort.
3.
Minimize the cost of processing millions of files.
4.
Support schema inference and schema drift. Which should you include in the recommendation?
A. COPY INTO
B. Azure Data Factory
C. Auto Loader
D. Apache Spark FileStreamSource
Correct Answer: C
Configure schema inference and evolution in Auto Loader You can configure Auto Loader to automatically detect the schema of loaded data, allowing you to initialize tables without explicitly declaring the data schema and evolve the table schema as new columns are introduced. This eliminates the need to manually track and apply schema changes over time.
Auto Loader can detect schema drifts, notify you when schema changes happen, and rescue data that would have been otherwise ignored or lost.
You are designing a solution that will use tables in Delta Lake on Azure Databricks. You need to minimize how long it takes to perform the following:
1.
Queries against non-partitioned tables
2.
Joins on non-partitioned columns
Which two options should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. the clone command
B. Z-Ordering
C. Apache Spark caching
D. dynamic file pruning (DFP)
Correct Answer: BD
Best practices: Delta Lake
B: Provide data location hints If you expect a column to be commonly used in query predicates and if that column has high cardinality (that is, a large number of distinct values), then use Z-ORDER BY. Delta Lake automatically lays out the data in the files based on the column values and uses the layout information to skip irrelevant data while querying.
BD: Dynamic file pruning, can significantly improve the performance of many queries on Delta Lake tables. Dynamic file pruning is especially efficient for non-partitioned tables, or for joins on non-partitioned columns. The performance impact
of dynamic file pruning is often correlated to the clustering of data so consider using Z-Ordering to maximize the benefit.
Incorrect:
Not C: Spark caching
Databricks does not recommend that you use Spark caching for the following reasons:
You lose any data skipping that can come from additional filters added on top of the cached DataFrame.
The data that gets cached might not be updated if the table is accessed using a different identifier (for example, you do spark.table(x).cache() but then write to the table using spark.write.save(/some/path).
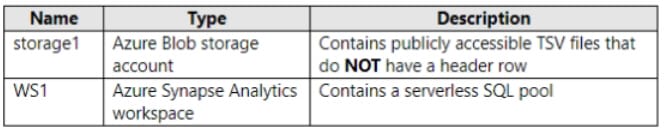
You have an Azure subscription that contains the resources shown in the following table.
You need to read the TSV files by using ad-hoc queries and the OPENROWSETfunction. The solution must assign a name and override the inferred data type of each column.
What should you include in the OPENROWSETfunction?
A. the WITH clause
B. the ROWSET_OPTIONSbulk option
C. the DATAFILETYPEbulk option
D. the DATA_SOURCEparameter
Correct Answer: D
Data source usage
Previous example uses full path to the file. As an alternative, you can create an external data source with the location that points to the root folder of the storage:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Once you create a data source, you can use that data source and the relative path to the file in OPENROWSET function:
select top 10 *
from openrowset( bulk 'latest/ecdc_cases.csv', data_source = 'covid', format = 'csv', parser_version ='2.0', firstrow = 2 ) as rows
Incorrect:
Not B: ROWSET_OPTIONS not need if there is no header.
You have an Azure Data Lake Storage Gen2 account named account1 that contains a container named container1.
You plan to create lifecycle management policy rules for container1.
You need to ensure that you can create rules that will move blobs between access tiers based on when each blob was accessed last.
What should you do first?
A. Configure object replication
B. Create an Azure application
C. Enable access time tracking
D. Enable the hierarchical namespace
Correct Answer: C
Generally available: Access time-based lifecycle management rules for Data Lake Storage Gen2
Some data in Azure Storage is written once and read many times. To effectively manage the lifecycle of such data and optimize your storage costs, it is important to know the last time of access for the data. When access time tracking is
enabled for a storage account, the last access time property on the file is updated when it is read. You can then define lifecycle management policies based on last access time:
Transition objects from hotter to cooler access tiers if the file has not been accessed for a specified duration.
Automatically transition objects from cooler to hotter access tiers when a file is accessed again.
Delete objects if they have not been accessed for an extended duration.
Access time tracking is only available for files in Data Lake Storage Gen2.
You have an Azure Data Factory pipeline named pipeline1 that includes a Copy activity named Copy1. Copy1 has the following configurations:
1.
The source of Copy1 is a table in an on-premises Microsoft SQL Server instance that is accessed by using a linked service connected via a self-hosted integration runtime.
2.
The sink of Copy1 uses a table in an Azure SQL database that is accessed by using a linked service connected via an Azure integration runtime.
You need to maximize the amount of compute resources available to Copy1. The solution must minimize administrative effort.
What should you do?
A. Scale out the self-hosted integration runtime.
B. Scale up the data flow runtime of the Azure integration runtime and scale out the self-hosted integration runtime.
C. Scale up the data flow runtime of the Azure integration runtime.
Correct Answer: C
Scaling the Azure integration runtime is easy with the UI. Scaling the self-hosted integration runtime requires more effort.
Copy activity performance optimization features
Configuring performance features with UI
Note: Data Integration Units
A Data Integration Unit is a measure that represents the power (a combination of CPU, memory, and network resource allocation) of a single unit within the service. Data Integration Unit only applies to Azure integration runtime, but not self-
hosted integration runtime.
The allowed DIUs to empower a copy activity run is between 2 and 256. If not specified or you choose "Auto" on the UI, the service dynamically applies the optimal DIU setting based on your source-sink pair and data pattern.
Incorrect:
Not A, Not B:
Self-hosted integration runtime scalability
If you would like to achieve higher throughput, you can either scale up or scale out the Self-hosted IR:
*
If the CPU and available memory on the Self-hosted IR node are not fully utilized, but the execution of concurrent jobs is reaching the limit, you should scale up by increasing the number of concurrent jobs that can run on a node.
*
If on the other hand, the CPU is high on the Self-hosted IR node or available memory is low, you can add a new node to help scale out the load across the multiple nodes.
You have an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
A. Connect to Pool1 and run DBCC PDW_SHOWSPACEUSED.
B. Connect to the built-in pool and run DBCC PDW_SHOWSPACEUSED.
C. Connect to the built-in pool and run DBCC CHECKALLOC.
D. Connect to the built-in pool and query sys.dm_pdw_sys_info.
Correct Answer: A
sys.dm_pdw_sys_info actually provides a set of appliance-level countersthat reflect overall activity on the appliance. DBCC PDW_SHOWSPACEUSEDshould be use instead since it displays the number of rows, disk spacereserved, and disk space used for a specific table, or for all tables ina Azure Synapse Analytics or Analytics Platform System (PDW) database.
Question 29:
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named DimSalesPerson. DimSalesPerson contains the following columns:
1.
RepSourceID
2.
SalesRepID
3.
FirstName
4.
LastName
5.
StartDate
6.
EndDate
7.
Region
You are developing an Azure Synapse Analytics pipeline that includes a mapping data flow named Dataflow1. Dataflow1 will read sales team data from an external source and use a Type 2 slowly changing dimension (SCD) when loading the
data into DimSalesPerson.
You need to update the last name of a salesperson in DimSalesPerson.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Update three columns of an existing row.
B. Update two columns of an existing row.
C. Insert an extra row.
D. Update one column of an existing row.
Correct Answer: CD
We insert a now row.
In the old row we update the EndDate column.
Note:
A Type 2 SCD supports versioning of dimension members. Often the source system doesn't store versions, so the data warehouse load process detects and manages changes in a dimension table. In this case, the dimension table must use
a surrogate key to provide a unique reference to a version of the dimension member. It also includes columns that define the date range validity of the version (for example, StartDate and EndDate) and possibly a flag column (for example,
IsCurrent) to easily filter by current dimension members.
Example (in this example there is a isCurrent column, but we have not it in here):
Adventure Works assigns salespeople to a sales region. When a salesperson relocates region, a new version of the salesperson must be created to ensure that historical facts remain associated with the former region. To support accurate
historic analysis of sales by salesperson, the dimension table must store versions of salespeople and their associated region(s). The table should also include start and end date values to define the time validity. Current versions may define
an empty end date (or 12/31/9999), which indicates that the row is the current version. The table must also define a surrogate key because the business key (in this instance, employee ID) won't be unique.
A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A. Azure Analysis Services using Azure PowerShell
B. Azure Stream Analytics Edge application using Microsoft Visual Studio
C. Azure Analysis Services using Microsoft Visual Studio
D. Azure Data Factory instance using Azure Portal
Correct Answer: B
Azure Stream Analytics on IoT Edge empowers developers to deploy near-real-time analytical intelligence closer to IoT devices so that they can unlock the full value of device-generated data.
You can use Stream Analytics tools for Visual Studio to author, debug, and create your Stream Analytics Edge jobs. After you create and test the job, you can go to the Azure portal to deploy it to your devices.
Incorrect:
Not A, not C: Azure Analysis Services is a fully managed platform as a service (PaaS) that provides enterprise-grade data models in the cloud. Use advanced mashup and modeling features to combine data from multiple data sources, define
metrics, and secure your data in a single, trusted tabular semantic data model.
Nowadays, the certification exams become more and more important and required by more and more
enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare
for the exam in a short time with less efforts? How to get a ideal result and how to find the
most reliable resources? Here on Vcedump.com, you will find all the answers.
Vcedump.com provide not only Microsoft exam questions,
answers and explanations but also complete assistance on your exam preparation and certification
application. If you are confused on your DP-203 exam preparations
and Microsoft certification application, do not hesitate to visit our
Vcedump.com to find your solutions here.