DP-203 Exam Details
-
Exam Code
:DP-203 -
Exam Name
:Data Engineering on Microsoft Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:422 Q&As -
Last Updated
:Oct 02, 2025
Microsoft DP-203 Online Questions & Answers
-
Question 311:
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.
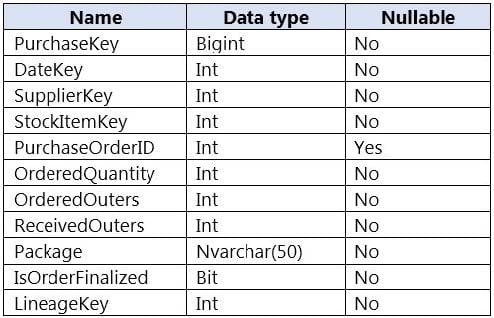
FactPurchase will have 1 million rows of data added daily and will contain three years of data.
Transact-SQL queries similar to the following query will be executed daily.
SELECT SupplierKey, StockItemKey, COUNT(*) FROM FactPurchase WHERE DateKey >= 20210101 AND DateKey <= 20210131 GROUP By SupplierKey, StockItemKey
Which table distribution will minimize query times?
A. replicated
B. hash-distributed on PurchaseKey
C. round-robin
D. hash-distributed on DateKey
-
Question 312:
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast columns to specified types of data, and insert the data into a table in an Azure Synapse Analytic dedicated SQL pool. The CSV file contains three columns named username, comment, and date.
The data flow already contains the following:
1.
A source transformation.
2.
A Derived Column transformation to set the appropriate types of data.
3.
A sink transformation to land the data in the pool.
You need to ensure that the data flow meets the following requirements:
1.
All valid rows must be written to the destination table.
2.
Truncation errors in the comment column must be avoided proactively.
3.
Any rows containing comment values that will cause truncation errors upon insert must be written to a file in blob storage.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. To the data flow, add a sink transformation to write the rows to a file in blob storage.
B. To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
C. To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
D. Add a select transformation to select only the rows that will cause truncation errors.
-
Question 313:
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is accessible only through an Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active Directory group named Sales. POSIX controls are used to assign the Sales group access to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each area selection is worth one point.
A. Add the managed identity to the Sales group.
B. Use the managed identity as the credentials for the data load process.
C. Create a shared access signature (SAS).
D. Add your Azure Active Directory (Azure AD) account to the Sales group.
E. Use the snared access signature (SAS) as the credentials for the data load process.
F. Create a managed identity.
-
Question 314:
You need to design an Azure Synapse Analytics dedicated SQL pool that meets the following requirements:
1.
Can return an employee record from a given point in time.
2.
Maintains the latest employee information.
3.
Minimizes query complexity. How should you model the employee data?
A. as a temporal table
B. as a SQL graph table
C. as a degenerate dimension table
D. as a Type 2 slowly changing dimension (SCD) table
-
Question 315:
You have an Azure Synapse workspace named MyWorkspace that contains an Apache Spark database named mytestdb.
You run the following command in an Azure Synapse Analytics Spark pool in MyWorkspace.
CREATE TABLE mytestdb.myParquetTable(EmployeeID int,EmployeeName string,EmployeeStartDate date)
USING Parquet
You then use Spark to insert a row into mytestdb.myParquetTable. The row contains the following data.

One minute later, you execute the following query from a serverless SQL pool in MyWorkspace.
SELECT EmployeeIDFROM mytestdb.dbo.myParquetTableWHERE EmployeeName = 'Alice';
What will be returned by the query?
A. 24
B. an error
C. a null value
-
Question 316:
You need to implement the surrogate key for the retail store table. The solution must meet the sales transaction dataset requirements. What should you create?
A. a table that has an IDENTITY property
B. a system-versioned temporal table
C. a user-defined SEQUENCE object
D. a table that has a FOREIGN KEY constraint
-
Question 317:
You have an Azure Storage account and a data warehouse in Azure Synapse Analytics in the UK South region.
You need to copy blob data from the storage account to the data warehouse by using Azure Data Factory. The solution must meet the following requirements:
Ensure that the data remains in the UK South region at all times.
Minimize administrative effort.
Which type of integration runtime should you use?
A. Azure integration runtime
B. Azure-SSIS integration runtime
C. Self-hosted integration runtime
-
Question 318:
You need to design a data retention solution for the Twitter teed data records. The solution must meet the customer sentiment analytics requirements.
Which Azure Storage functionality should you include in the solution?
A. time-based retention
B. change feed
C. soft delete
D. Iifecycle management
-
Question 319:
You need to integrate the on-premises data sources and Azure Synapse Analytics. The solution must meet the data integration requirements. Which type of integration runtime should you use?
A. Azure-SSIS integration runtime
B. self-hosted integration runtime
C. Azure integration runtime



Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-203 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.