DP-203 Exam Details
-
Exam Code
:DP-203 -
Exam Name
:Data Engineering on Microsoft Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:422 Q&As -
Last Updated
:Oct 02, 2025
Microsoft DP-203 Online Questions & Answers
-
Question 41:
You have an Azure Data Lake Storage Gen2 account named storage1.
You plan to implement query acceleration for storage1.
Which two file types support query acceleration? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. JSON
B. Apache Parquet
C. XML
D. CSV
E. Avro
-
Question 42:
You have two Azure Blob Storage accounts named account1 and account2.
You plan to create an Azure Data Factory pipeline that will use scheduled intervals to replicate newly created or modified blobs from account1 to account2.
You need to recommend a solution to implement the pipeline. The solution must meet the following requirements:
1.
Ensure that the pipeline only copies blobs that were created or modified since the most recent replication event.
2.
Minimize the effort to create the pipeline. What should you recommend?
A. Run the Copy Data tool and select Metadata-driven copy task.
B. Create a pipeline that contains a Data Flow activity.
C. Create a pipeline that contains a flowlet.
D. Run the Copy Data tool and select Built-in copy task.
-
Question 43:
You plan to use an Apache Spark pool in Azure Synapse Analytics to load data to an Azure Data Lake Storage Gen2 account.
You need to recommend which file format to use to store the data in the Data Lake Storage account. The solution must meet the following requirements:
Column names and data types must be defined within the files loaded to the Data Lake Storage account. Data must be accessible by using queries from an Azure Synapse Analytics serverless SQL pool. Partition elimination must be
supported without having to specify a specific partition.
What should you recommend?
A. Delta Lake
B. JSON
C. CSV
D. ORC
-
Question 44:
You are deploying a lake database by using an Azure Synapse database template.
You need to add additional tables to the database. The solution must use the same grouping method as the template tables.
Which grouping method should you use?
A. business area
B. size
C. facts and dimensions
D. partition style
-
Question 45:
You have an Azure subscription that is linked to a tenant in Microsoft Azure Active Directory (Azure AD), part of Microsoft Entra. The tenant that contains a security group named Group1. The subscription contains an Azure Data Lake Storage
account named myaccount1. The myaccount1 account contains two containers named container1 and container2.
You need to grant Group1 read access to container1. The solution must use the principle of least privilege.
Which role should you assign to Group1?
A. Storage Table Data Reader for myaccount1
B. Storage Blob Data Reader for container1
C. Storage Blob Data Reader for myaccount1
D. Storage Table Data Reader for container1
-
Question 46:
You are designing a dimension table in an Azure Synapse Analytics dedicated SQL pool.
You need to create a surrogate key for the table. The solution must provide the fastest query performance.
What should you use for the surrogate key?
A. a GUID column
B. a sequence object
C. an IDENTITY column
-
Question 47:
You have an Azure data factory that connects to a Microsoft Purview account. The data factory is registered in Microsoft Purview.
You update a Data Factory pipeline.
You need to ensure that the updated lineage is available in Microsoft Purview.
What should you do first?
A. Locate the related asset in the Microsoft Purview portal.
B. Execute the pipeline.
C. Disconnect the Microsoft Purview account from the data factory.
D. Execute an Azure DevOps build pipeline.
-
Question 48:
You have an Azure subscription that contains an Azure SQL database named DB1 and a storage account named storage1. The storage1 account contains a file named File1.txt. File1.txt contains the names of selected tables in DB1. You need to use an Azure Synapse pipeline to copy data from the selected tables in DB1 to the files in storage1. The solution must meet the following requirements:
1.
The Copy activity in the pipeline must be parameterized to use the data in File1.txt to identify the source and destination of the copy.
2.
Copy activities must occur in parallel as often as possible.
Which two pipeline activities should you include in the pipeline? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. If Condition
B. ForEach
C. Lookup
D. Get Metadata
-
Question 49:
You have an Azure subscription that contains a Microsoft Purview account named MP1, an Azure data factory named DF1, and a storage account named storage. MP1 is configured 10 scan storage1. DF1 is connected to MP1 and contains 3
dataset named DS1. DS1 references 2 file in storage.
In DF1, you plan to create a pipeline that will process data from DS1.
You need to review the schema and lineage information in MP1 for the data referenced by DS1.
Which two features can you use to locate the information? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
A. the Storage browser of storage1 in the Azure portal
B. the search bar in the Azure portal
C. the search bar in Azure Data Factory Studio
D. the search bar in the Microsoft Purview governance portal
-
Question 50:
You have a Microsoft Purview account. The Lineage view of a CSV file is shown in the following exhibit.
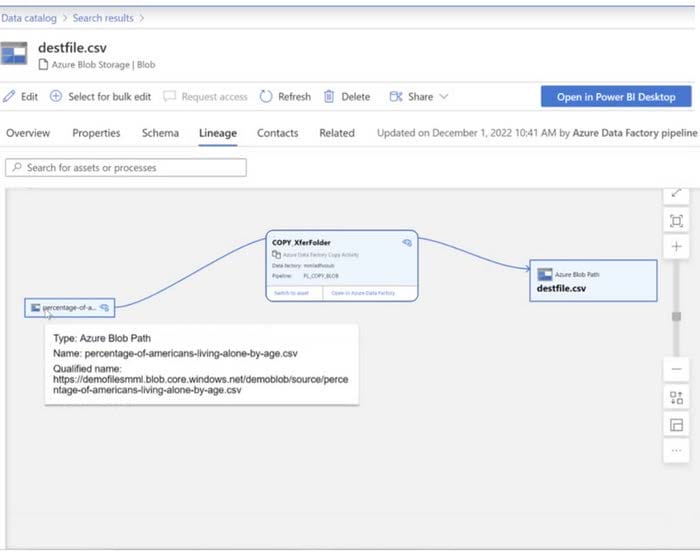
How is the data for the lineage populated?
A. manually
B. by scanning data stores
C. by executing a Data Factory pipeline
Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-203 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.