DP-100 Exam Details
-
Exam Code
:DP-100 -
Exam Name
:Designing and Implementing a Data Science Solution on Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:617 Q&As -
Last Updated
:Jul 17, 2026
Microsoft DP-100 Online Questions & Answers
-
Question 201:
You have been tasked with employing a machine learning model, which makes use of a PostgreSQL database and needs GPU processing, to forecast prices.
You are preparing to create a virtual machine that has the necessary tools built into it.
You need to make use of the correct virtual machine type.
Recommendation: You make use of a Deep Learning Virtual Machine (DLVM) Windows edition.
Will the requirements be satisfied?
A. Yes
B. No -
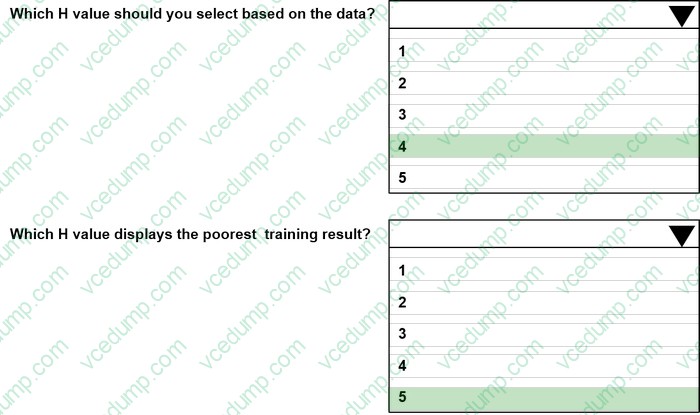
Question 202:
HOTSPOT
You are tuning a hyperparameter for an algorithm. The following table shows a data set with different hyperparameter, training error, and validation errors.
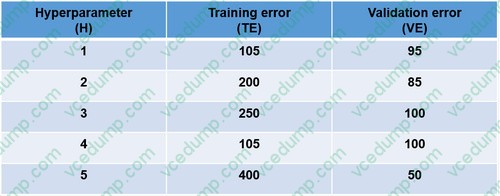
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
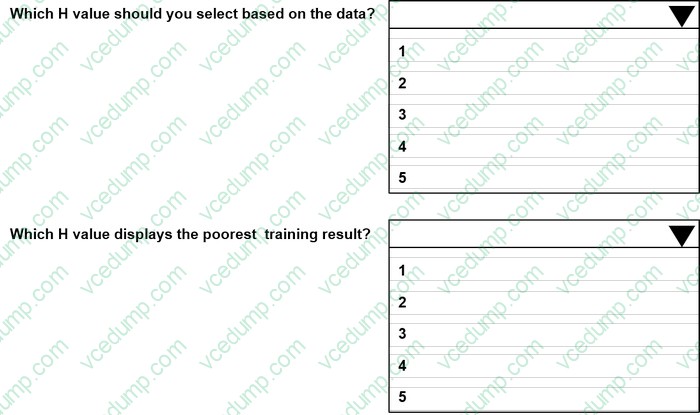
-
Question 203:
You are in the process of creating a machine learning model. Your dataset includes rows with null and missing values.
You plan to make use of the Clean Missing Data module in Azure Machine Learning Studio to detect and fix the null and missing values in the dataset.
Recommendation: You make use of the Remove entire row option.
Will the requirements be satisfied?
A. Yes
B. No -
Question 204:
You have the following Azure subscriptions and Azure Machine Learning service workspaces:

You need to obtain a reference to the ml-project workspace.
Solution: Run the following Python code:
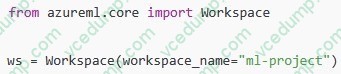
Does the solution meet the goal?
A. Yes
B. No -
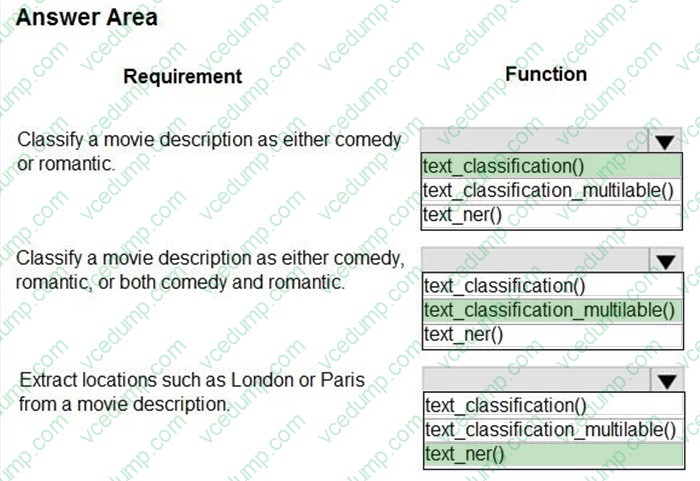
Question 205:
HOTSPOT
You create a list of movie descriptions in text data format.
You must analyze the movie descriptions with automated machine learning.
You need to use the Azure Machine Learning for Python SDK v1 to configure a job with the specific natural language processing (NLP) task function for AutoML jobs.
Which functions should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
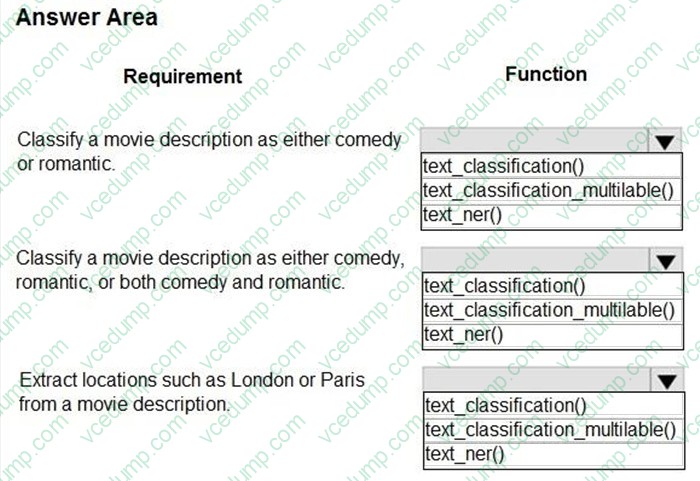
-
Question 206:
You create an Azure Machine Learning workspace named workspace1. The workspace contains a Python SDK v2 notebook that uses MLflow to collect model training metrics and artifacts from your local computer.
You must reuse the notebook to run on Azure Machine Learning compute instance in workspace1.
You need to continue to log metrics and artifacts from your data science code.
What should you do?
A. Instantiate the job class.
B. Instantiate the MLCIient class.
C. Log in to workspace1.
D. Configure the tracking URL. -
Question 207:
DRAG DROP
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
Data scientists must build notebooks in a cloud environment
Data scientists must use automatic feature engineering and model building in machine learning pipelines.
Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
Notebooks must be exportable to be version controlled locally.
You need to create the environment.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

-
Question 208:
You need to evaluate the potential risk of exposing personal information based on the values of epsilon and delta for differential privacy. You create a privacy report.
What does an epsilon value greater than one represent?
A. The privacy of data is preserved and there is limited impact on data accuracy.
B. There is a high risk of exposing the actual data that is uses to generate the report.
C. The data used in the report is very noisy. -
Question 209:
HOTSPOT
You build a data pipeline in an Azure Machine Learning workspace by using the Azure Machine Learning SDK for Python. You create a data preparation step in the data pipeline.
You create the following code fragment in Python:

For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

-
Question 210:
You are reviewing model benchmarks in Azure AI Foundry.
You must use an embedding model that can assess rank-order relevance based on cosine similarity.
You need to select the applicable embedding model metric.
Which metric should you focus on?
A. V-measure
B. Mean average precision
C. F1 score
D. Spearman correlation


Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.