DP-100 Exam Details
-
Exam Code
:DP-100 -
Exam Name
:Designing and Implementing a Data Science Solution on Azure -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:617 Q&As -
Last Updated
:Jul 17, 2026
Microsoft DP-100 Online Questions & Answers
-
Question 141:
HOTSPOT
You have an Azure AI Foundry project that contains a flow with two nodes: Node1 and Node2.
You plan to create three variants for each node and test how well different variants perform.
You need to submit flow runs from Azure AI Foundry and evaluate the resulting variant runs.
What is the minimum number of runs you should plan for?
NOTE: Each correct selection is worth one point.

-
Question 142:
You use the Azure Machine Learning SDK for Python v1 and notebooks to train a model. You create a compute target, an environment, and a training script by using Python code.
You need to prepare information to submit a training run.
Which class should you use?
A. ScriptRun
B. ScriptRunConfig
C. RunConfiguration
D. Run -
Question 143:
DRAG DROP
You are designing an Azure Machine Learning solution.
The model must be trained by using automated machine learning. The compute must be a shared resource with users in the Azure Machine Learning workspace. After you train the model, it must be deployed for batch scoring on a serverless compute.
You need to select the appropriate computation options for the solution.
Which compute options should you select for training and deployment? To answer, move the appropriate compute options to the correct project activities. You may use each compute option once, more than once, or not at all. You may need to move the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

-
Question 144:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
1. /data/2018/Q1.csv
2. /data/2018/Q2.csv
3. /data/2018/Q3.csv
4. /data/2018/Q4.csv
5. /data/2019/Q1.csv
All files store data in the following format:
id,f1,f2,I
1,1,2,0
2,1,1,1
3,2,1,0
4,2,2,1
You run the following code:

You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:

Solution: Run the following code:

Does the solution meet the goal?
A. Yes
B. No -
Question 145:
You are building a regression model for estimating the number of calls during an event.
You need to determine whether the feature values achieve the conditions to build a Poisson regression model.
Which two conditions must the feature set contain? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. The label data must be a negative value.
B. The label data must be whole numbers.
C. The label data must be non-discrete.
D. The label data must be a positive value.
E. The label data can be positive or negative. -
Question 146:
HOTSPOT
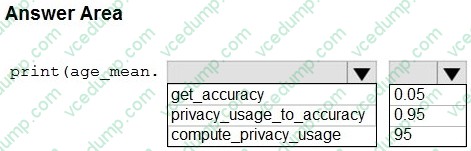
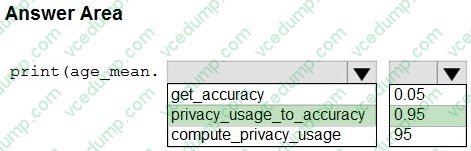
You create an Azure Machine Learning workspace and a dataset. The dataset includes age values for a large group of diabetes patients. You use the dp.mean function from the SmartNoise library to calculate the mean of the age value. You store the value in a variable named age.mean.
You must output the value of the interval range of released mean values that will be returned 95 percent of the time.
You need to complete the code.
Which code values should you use? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.
-
Question 147:
You have an Azure Machine Learning workspace.
You plan to run a job to tram a model as an MLflow model output.
You need to specify the output mode of the MLflow model.
Which three modes can you specify? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. rw_mount
B. ro mount
C. upload
D. download
E. direct -
Question 148:
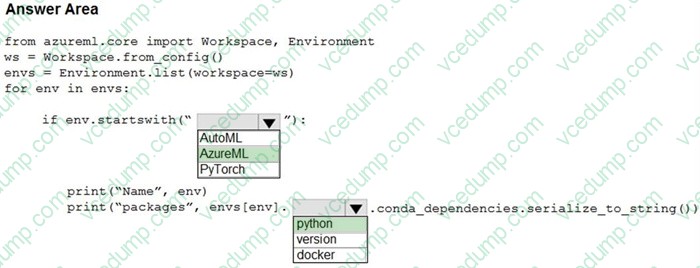
HOTSPOT
You plan to use a curated environment to run Azure Machine Learning training experiments in a workspace.
You need to display all curated environments and their respective packages in the workspace.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

-
Question 149:
You plan to run a script as an experiment. The script uses modules from the SciPy library and several Python packages that are not typically installed in a default conda environment.
You plan to run the experiment on your local workstation for small datasets and scale out the experiment by running it on more powerful remote compute dusters for larger datasets.
You need to ensure that the experiment runs successfully on local and remote compute with the least administrative effort.
What should you do?
A. Leave the environment unspecified for the experiment. Run the expenment by using the default environment.
B. Create a config.yaml file that defines the required conda packages and save the file in the experiment folder.
C. Create and register an environment that includes the required packages. Use this environment for all experiment jobs.
D. Create a virtual machine (VM) by using the required Python configuration and attach the VM as a compute target. Use this compute target for all experiment runs. -
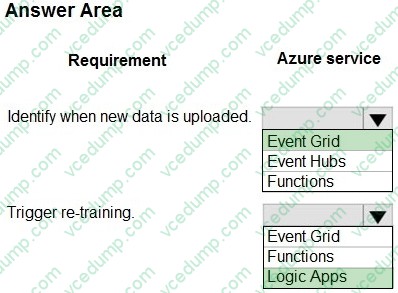
Question 150:
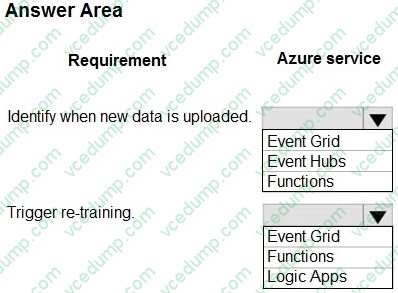
HOTSPOT
You train a model by using Azure Machine Learning. You use Azure Blob Storage to store production data.
The model must be re-trained when new data is uploaded to Azure Blob Storage. You need to minimize development and coding.
You need to configure Azure services to develop a re-training solution.
Which Azure services should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DP-100 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.