DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE Exam Details
-
Exam Code
:DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE -
Exam Name
:Databricks Certified Data Engineer Associate -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:196 Q&As -
Last Updated
:Jul 11, 2026
Databricks DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE Online Questions & Answers
-
Question 51:
Which of the following statements best describes the role of Silver tables in the Medallion architecture?
A. Store raw ingested data from source systems.
B. Store cleaned and refined data ready for analysis.
C. Store business-level aggregated data.
D. Store archived data for compliance.
E. Store feature-engineered datasets for ML. -
Question 52:
A data engineer needs to develop integration tests for an ETL process and deploy a version-controlled, packaged workflow into production using an external job scheduler. Which tool should the data engineer use for this job?
A. Databricks Connect
B. Databricks Asset Bundles
C. Databricks Command Line Interface
D. Databricks Software Development Kit -
Question 53:
Which SQL code snippet will correctly demonstrate a Data Definition Language (DDL) operation used to create a table?
A. CREATE TABLE employees ( id INT, name STRING );
B. DROP TABLE employees;
C. ALTER TABLE employees ADD COLUMN salary DECIMAL(10,2);
D. INSERT INTO employees (id, name) VALUES (1 'Alice'); -
Question 54:
A data engineer has written a function in a Databricks Notebook to calculate the population of bacteria in a given medium.
def calculate_population_of_bacteria (intital_population, exponential_factor):
return future_population = intital_population ** exponential_factor
Analysts use this function in the notebook and sometimes provide input arguments of the wrong data type, which can cause errors during execution.
Which Databricks feature will help the data engineer quickly identify if an incorrect data type has been provided as input?
A. The Spark User interface has a debug tab that contains the variables that are used in this session.
B. The Databricks debugger enables breakpoints that will raise an error if the wrong data type is submitted.
C. The Databricks debugger enables the use of a variable explorer to see at a glance the value of the variables.
D. The Data Engineer should add print statements to find out what the variable is. -
Question 55:
A global retail company sells products across multiple categories (e.g., Electronics, Clothing) and regions (e.g., North, South, East, West). The sales team has provided the data engineer with a PySpark dataframe named sales_df as below and the team wants the data engineer to analyze the sales data to help them make strategic decisions.
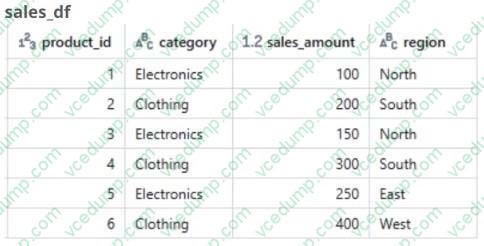
Calculate the total sales amount for each product category and store the results in a new dataframe called . category_sales
What will generate the expected result of category_sales?
A. category_sales = sales_df.groupBy("category").agg(sum("sales_amount").alias ("total_sales_amount"))
B. category_sales = sales_df.sum("sales_amount").groupBy("category").alias ("total_sales_amount"))
C. category_sales = sales_df.agg(sum("sales_amount").groupBy("category").alias ("total_sales_amount"))
D. category_sales = sales_df.groupBy("region").agg(sum("sales_amount").alias ("total_sales_amount")) -
Question 56:
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > '2020-01-01') ON VIOLATION FAIL UPDATE
What is the expected behavior when a batch of data containing data that violates these constraints is processed?
A. Records that violate the expectation are dropped from the target dataset and recorded as invalid in the event log.
B. Records that violate the expectation cause the job to fail.
C. Records that violate the expectation are dropped from the target dataset and loaded into a quarantine table.
D. Records that violate the expectation are added to the target dataset and recorded as invalid in the event log.
E. Records that violate the expectation are added to the target dataset and flagged as invalid in a field added to the target dataset. -
Question 57:
A data engineer needs access to a table new_uable, but they do not have the correct permissions. They can ask the table owner for permission, but they do not know who the table owner is. Which approach can be used to identify the owner of new_table?
A. There is no way to identify the owner of the table
B. Review the Owner field in the table's page in the cloud storage solution
C. Review the Permissions tab in the table's page in Data Explorer
D. Review the Owner field in the table's page in Data Explorer -
Question 58:
Which two conditions are applicable for governance in Databricks Unity Catalog? (Choose two.)
A. You can have more than 1 metastore within a databricks account console but only 1 per region.
B. Both catalog and schema must have a managed location in Unity Catalog provided metastore is not associated with a location
C. You can have multiple catalogs within metastore and 1 catalog can be associated with multiple metastore
D. If catalog is not associated with location, it's mandatory to associate schema with managed locations
E. If metastore is not associated with location, it's mandatory to associate catalog with managed locations AE -
Question 59:
A data engineer is attempting to drop a Spark SQL table my_table and runs the following command:
DROP TABLE IF EXISTS my_table;
After running this command, the engineer notices that the data files and metadata files have been deleted from the file system.
Which of the following describes why all of these files were deleted?
A. The table was managed
B. The table's data was smaller than 10 GB
C. The table's data was larger than 10 GB
D. The table was external
E. The table did not have a location -
Question 60:
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
A. Worker node
B. JDBC data source
C. Databricks web application
D. Databricks Filesystem
E. Driver node
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.