DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE Exam Details
-
Exam Code
:DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE -
Exam Name
:Databricks Certified Data Engineer Associate -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:196 Q&As -
Last Updated
:Jul 11, 2026
Databricks DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE Online Questions & Answers
-
Question 11:
How do you grant all privileges on a table to a group in Databricks SQL?
A. GRANT ALL TO group ON TABLE
B. GRANT FULL ACCESS TO group ON TABLE
C. GRANT ALL PRIVILEGES ON TABLE table_name TO group
D. GRANT USAGE ON TABLE TO group
E. GRANT MODIFY ON TABLE TO group -
Question 12:
Which of the following commands will return the location of database customer360?
A. DESCRIBE LOCATION customer360;
B. DROP DATABASE customer360;
C. DESCRIBE DATABASE customer360;
D. ALTER DATABASE customer360 SET DBPROPERTIES ('location' = '/user'};
E. USE DATABASE customer360; -
Question 13:
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
A. REDUCE
B. OPTIMIZE
C. COMPACTION
D. REPARTITION
E. VACUUM -
Question 14:
A data engineer needs to conduct Exploratory Analysis on data residing in a database that is within the company's custom-defined network in the cloud. The data engineer is using SQL for this task. Which type of SQL Warehouse will enable the data engineer to process large numbers of queries quickly and cost-effectively?
A. Serverless compute for notebooks
B. Pro SQL Warehouse
C. Classic SQL Warehouse
D. Serverless SQL Warehouse -
Question 15:
A data engineering team has noticed that their Databricks SQL queries are running too slowly when they are submitted to a non-running SQL endpoint. The data engineering team wants this issue to be resolved. Which of the following approaches can the team use to reduce the time it takes to return results in this scenario?
A. They can turn on the Serverless feature for the SQL endpoint and change the Spot Instance Policy to "Reliability Optimized."
B. They can turn on the Auto Stop feature for the SQL endpoint.
C. They can increase the cluster size of the SQL endpoint.
D. They can turn on the Serverless feature for the SQL endpoint.
E. They can increase the maximum bound of the SQL endpoint's scaling range -
Question 16:
A data engineer has been provided a PySpark DataFrame named df with columns product and revenue. The data engineer needs to compute complex aggregations to determine each product's total revenue, average revenue, and transaction count.
Which code snippet should the data engineer use?
A. Option A
B. Option B
C. Option C
D. Option D -
Question 17:
Which of the following tools is used by Auto Loader process data incrementally?
A. Checkpointing
B. Spark Structured Streaming
C. Data Explorer
D. Unity Catalog
E. Databricks SQL -
Question 18:
Which of the following benefits is provided by the array functions from Spark SQL?
A. An ability to work with data in a variety of types at once
B. An ability to work with data within certain partitions and windows
C. An ability to work with time-related data in specified intervals
D. An ability to work with complex, nested data ingested from JSON files
E. An ability to work with an array of tables for procedural automation -
Question 19:
A data engineer needs to create a table in Databricks using data from their organization's existing SQLite database.
They run the following command:
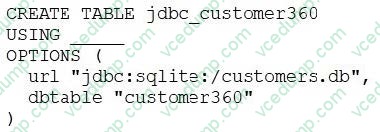
Which of the following lines of code fills in the above blank to successfully complete the task?
A. org.apache.spark.sql.jdbc
B. autoloader
C. DELTA
D. sqlite
E. org.apache.spark.sql.sqlite -
Question 20:
A data engineer is reviewing the documentation on audit logs in Databricks for compliance purposes and needs to understand the format in which audit logs output events. How are events formatted in Databricks audit logs?
A. In Databricks, audit logs output events in a JSON format.
B. In Databricks, audit logs output events in a CSV format.
C. In Databricks, audit logs output events in an XML format.
D. In Databricks, audit logs output events in a plain text format.
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.