DATA-ENGINEER-ASSOCIATE Exam Details
-
Exam Code
:DATA-ENGINEER-ASSOCIATE -
Exam Name
:AWS Certified Data Engineer - Associate (DEA-C01) -
Certification
:Amazon Certifications -
Vendor
:Amazon -
Total Questions
:403 Q&As -
Last Updated
:Jul 16, 2026
Amazon DATA-ENGINEER-ASSOCIATE Online Questions & Answers
-
Question 161:
A company uses Amazon S3 to store semi-structured data in a transactional data lake. Some of the data files are small, but other data files are tens of terabytes.
A data engineer must perform a change data capture (CDC) operation to identify changed data from the data source. The data source sends a full snapshot as a JSON file every day and ingests the changed data into the data lake.
Which solution will capture the changed data MOST cost-effectively?
A. Create an AWS Lambda function to identify the changes between the previous data and the current data. Configure the Lambda function to ingest the changes into the data lake.
B. Ingest the data into Amazon RDS for MySQL. Use AWS Database Migration Service (AWS DMS) to write the changed data to the data lake.
C. Use an open source data lake format to merge the data source with the S3 data lake to insert the new data and update the existing data.
D. Ingest the data into an Amazon Aurora MySQL DB instance that runs Aurora Serverless. Use AWS Database Migration Service (AWS DMS) to write the changed data to the data lake. -
Question 162:
A data engineer created a table named cloudtrail_logs in Amazon Athena to query AWS CloudTrail logs and prepare data for audits. The data engineer needs to write a query to display errors with error codes that have occurred since the beginning of 2024. The query must return the 10 most recent errors.
Which query will meet these requirements?
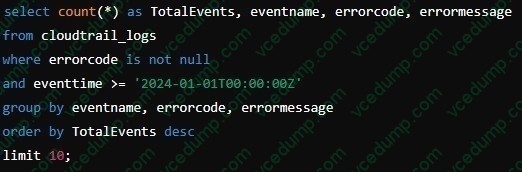
A. select count (*) as TotalEvents, eventname, errorcode, errormessage from cloudtrail_logswhere errorcode is not nulland eventtime >= '2024-01-01T00:00:00Z' group by eventname, errorcode, errormessageorder by TotalEvents desclimit 10;
B. select count (*) as TotalEvents, eventname, errorcode, errormessage from cloudtrail_logs where eventtime >= '2024-01-01T00:00:00Z' group by eventname, errorcode, errormessage order by TotalEvents desc limit 10;
C. select count (*) as TotalEvents, eventname, errorcode, errormessage from cloudtrail_logswhere eventtime >= '2024-01-01T00:00:00Z' group by eventname, errorcode, errormessageorder by eventname asc limit 10;
D. select count (*) as TotalEvents, eventname, errorcode, errormessage from cloudtrail_logs where errorcode is not nulland eventtime >= '2024-01-01T00:00:00Z' group by eventname, errorcode, errormessagelimit 10; -
Question 163:
A data engineer needs to debug an AWS Glue job that reads from Amazon S3 and writes to Amazon Redshift. The data engineer enabled the bookmark feature for the AWS Glue job. The data engineer has set the maximum concurrency for the AWS Glue job to 1.
The AWS Glue job is successfully writing the output to Amazon Redshift. However, the Amazon S3 files that were loaded during previous runs of the AWS Glue job are being reprocessed by subsequent runs.
What is the likely reason the AWS Glue job is reprocessing the files?
A. The AWS Glue job does not have the s3:GetObjectAcl permission that is required for bookmarks to work correctly.
B. The maximum concurrency for the AWS Glue job is set to 1.
C. The data engineer incorrectly specified an older version of AWS Glue for the Glue job.
D. The AWS Glue job does not have a required commit statement. -
Question 164:
Two business units use separate Amazon Redshift Serverless workgroups. The finance team owns a curated sales dataset and wants the marketing team to query the latest data without copying it or running nightly unload and load jobs.
Which approach should a data engineer choose?
A. Create an Amazon Redshift datashare from the finance workgroup and authorize the marketing workgroup to consume it.
B. Schedule an UNLOAD from the finance workgroup to Amazon S3 and a COPY into the marketing workgroup every hour.
C. Use AWS DataSync to synchronize Redshift table files between the two workgroups.
D. Export the sales dataset to Amazon DynamoDB global tables and query the data from both workgroups. -
Question 165:
An ecommerce company collects daily customer transaction logs in CSV format and stores the logs in Amazon S3. The company uses Amazon Athena to scan a subset of attributes from the logs on the same day the company receives each log.
Query times are increasing because of increasing transaction volume. The company wants to improve query performance.
Which solution will meet these requirements with the SHORTEST query times?
A. Convert the CSV logs into multiple ORC files for better parallelism in Athena. Partition by date in Amazon S3. Use columnar pushdown filters.
B. Convert the CSV logs to JSON. Partition by date in Amazon S3. Use Athena with dynamic filtering to reduce data scans.
C. Convert the CSV logs to Avro. Partition by date in Amazon S3. Use Athena with projection-based partitioning.
D. Convert the CSV logs to a single Apache Parquet file for each day Partition the data by date in Amazon S3. Use Athena with predicate pushdown filters. -
Question 166:
A company uses a data stream in Amazon Kinesis Data Streams to collect transactional data from multiple sources. The company uses an AWS Glue extract, transform, and load (ETL) pipeline to look for outliers in the data from the stream. When the workflow detects an outlier, it sends a notification to an Amazon Simple Notification Service (Amazon SNS) topic. The SNS topic initiates a second workflow to retrieve logs for the outliers and stores the logs in an Amazon S3 bucket. The company experiences delays in the notifications to the SNS topic during periods when the data stream is processing a high volume of data.
When the company examines Amazon CloudWatch logs, the company notices a high value for the glue.driver. BlockManager.disk.diskSpaceUsed_MB metric when the traffic is high. The company must resolve this issue.
Which solution will meet this requirement with the LEAST operational effort?
A. Increase the number of data processing units (DPUs) in AWS Glue ETL jobs.
B. Use Amazon EMR to manage the ETL pipeline instead of AWS Glue.
C. Use AWS Step Functions to orchestrate a parallel workflow state.
D. Enable auto scaling for the AWS Glue ETL jobs. -
Question 167:
A company stores raw audit records in Amazon S3. Records must remain immediately accessible for 90 days, then move to a lower-cost archive storage class, and then be deleted after 7 years.
Which solution should a data engineer implement?
A. Create an S3 Lifecycle policy with transition and expiration actions for the audit record prefix.
B. Create an AWS Glue crawler that runs every 90 days and changes the S3 storage class.
C. Create an Amazon EventBridge rule that deletes and reloads the objects after 7 years.
D. Create a DynamoDB TTL attribute for each S3 object key. -
Question 168:
A retail company stores customer data in an Amazon S3 bucket. Some of the customer data contains personally identifiable information (PII) about customers. The company must not share PII data with business partners.
A data engineer must determine whether a dataset contains PII before making objects in the dataset available to business partners.
Which solution will meet this requirement with the LEAST manual intervention?
A. Configure the S3 bucket and S3 objects to allow access to Amazon Macie. Use automated sensitive data discovery in Macie.
B. Configure AWS CloudTrail to monitor S3 PUT operations. Inspect the CloudTrail trails to identify operations that save PII.
C. Create an AWS Lambda function to identify PII in S3 objects. Schedule the function to run periodically.
D. Create a table in AWS Glue Data Catalog. Write custom SQL queries to identify PII in the table. Use Amazon Athena to run the queries. -
Question 169:
A security company stores IoT data that is in JSON format in an Amazon S3 bucket. The data structure can change when the company upgrades the IoT devices. The company wants to create a data catalog that includes the IoT data. The company's analytics department will use the data catalog to index the data.
Which solution will meet these requirements MOST cost-effectively?
A. Create an AWS Glue Data Catalog. Configure an AWS Glue Schema Registry. Create a new AWS Glue workload to orchestrate the ingestion of the data that the analytics department will use into Amazon Redshift Serverless.
B. Create an Amazon Redshift provisioned cluster. Create an Amazon Redshift Spectrum database for the analytics department to explore the data that is in Amazon S3. Create Redshift stored procedures to load the data into Amazon Redshift.
C. Create an Amazon Athena workgroup. Explore the data that is in Amazon S3 by using Apache Spark through Athena. Provide the Athena workgroup schema and tables to the analytics department.
D. Create an AWS Glue Data Catalog. Configure an AWS Glue Schema Registry. Create AWS Lambda user defined functions (UDFs) by using the Amazon Redshift Data API. Create an AWS Step Functions job to orchestrate the ingestion of the data that the analytics department will use into Amazon Redshift Serverless. -
Question 170:
A data engineering team already runs Kubernetes workloads on Amazon EKS. The team must run Apache Spark jobs in that environment and wants AWS to manage the Spark runtime while the team uses Kubernetes-native scaling patterns.
Which solution best fits these requirements?
A. Run Amazon EMR on Amazon EKS for the Spark jobs.
B. Install a self-managed Spark cluster on Amazon EC2 instances outside the EKS cluster.
C. Use Amazon RDS read replicas to execute the Spark jobs.
D. Use AWS Transfer Family to launch Spark pods in the EKS cluster.
Related Exams:
-
AIF-C01
Amazon AWS Certified AI Practitioner (AIF-C01) -
AIP-C01
AWS Certified Generative AI Developer - Professional -
ANS-C00
AWS Certified Advanced Networking - Specialty (ANS-C00) -
ANS-C01
AWS Certified Advanced Networking - Specialty (ANS-C01) -
AXS-C01
AWS Certified Alexa Skill Builder - Specialty (AXS-C01) -
BDS-C00
AWS Certified Big Data - Speciality (BDS-C00) -
CLF-C02
AWS Certified Cloud Practitioner (CLF-C02) -
DAS-C01
AWS Certified Data Analytics - Specialty (DAS-C01) -
DATA-ENGINEER-ASSOCIATE
AWS Certified Data Engineer - Associate (DEA-C01) -
DBS-C01
AWS Certified Database - Specialty (DBS-C01)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Amazon exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATA-ENGINEER-ASSOCIATE exam preparations and Amazon certification application, do not hesitate to visit our Vcedump.com to find your solutions here.