70-767 Exam Details
-
Exam Code
:70-767 -
Exam Name
:Implementing a SQL Data Warehouse -
Certification
:Microsoft Certifications -
Vendor
:Microsoft -
Total Questions
:402 Q&As -
Last Updated
:Jan 28, 2022
Microsoft 70-767 Online Questions & Answers
-
Question 301:
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database administrator for an e-commerce company that runs an online store. The company has the databases described in the following table.

Each week, you import a product catalog from a partner company to a staging table in DB2.
You need to create a stored procedure that will update the staging table by inserting new products and deleting discontinued products.
What should you use?
A. Lookup transformation
B. Merge transformation
C. Merge Join transformation
D. MERGE statement
E. Union All transformation
F. Balanced Data Distributor transformation
G. Sequential container
H. Foreach Loop container -
Question 302:
To facilitate the troubleshooting of SQL Server Integration Services (SSIS) packages, a logging methodology is put in place. The methodology has the following requirements:
A. Open a command prompt and run the gacutil command.
B. Open a command prompt and execute the package by using the SQL Log provider and running the dtexecui.exe utility.
C. Add an OnError event handler to the SSIS project.
D. Use an msi file to deploy the package on the server.
E. Configure the output of a component in the package data flow to use a data tap.
F. Run the dtutil command to deploy the package to the SSIS catalog and store the configuration in SQL Server.
G. Open a command prompt and run the dtexec /rep /conn command.
H. Open a command prompt and run the dtutil /copy command.
I. Open a command prompt and run the dtexec /dumperror /conn command.
J. Configure the SSIS solution to use the Project Deployment Model. -
Question 303:
HOTSPOT
You are using the Master Data Services (MDS) Add-in for Excel to configure the entities in a model. The model consists of two entities: one named Customer and one named State.
You open the Customer entity.
Currently, data stewards can enter any text value in the Customer entity's State attribute.
You must restrict the entry of values in the State attribute to members defined in the State entity.
You need to configure the State attribute of the Customer entity.
Which option should you use? (To answer, select the appropriate area in the answer area.)
Hot Area:
-
Question 304:
DRAG DROP
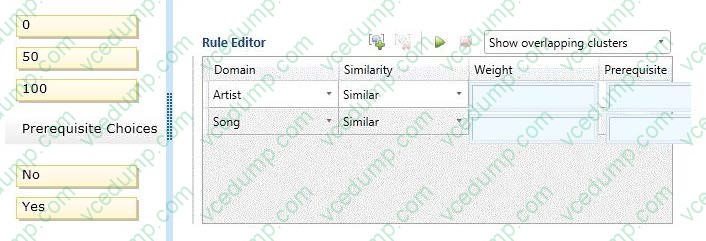
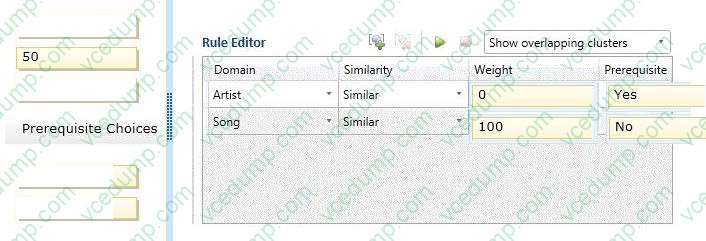
You are loading a dataset into SQL Server. The dataset contains numerous duplicates for the Artist and Song columns.
The values in the Artist column in the dataset must exactly match the values in the Artist domain in the knowledge base. The values in the Song column in the dataset can be a close match with the values in the Song domain.
You need to use SQL Server Data Quality Services (DQS) to define a matching policy rule to identify duplicates.
How should you configure the Rule Editor? (To answer, drag the appropriate answers to the answer area.)
Select and Place:
-
Question 305:
You need to configure Microsoft SQL Server Integration Services (SSIS) for maximum insert performance.
The Integration Services package is configured as shown in the following exhibit.(Missing exhibit)
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:

-
Question 306:
A SQL Server Integration Services (SSIS) package imports daily transactions from several files into a SQL Server table named Transaction. Each file corresponds to a different store and is imported in parallel with the other files. The data flow tasks use OLE DB destinations in fast load data access mode.
The number of daily transactions per store can be very large and is growing. The Transaction table does not have any indexes.
You need to minimize the package execution time.
What should you do?
A. Partition the table by day and store.
B. Create a clustered index on the Transaction table.
C. Run the package in Performance mode.
D. Increase the value of the Row per Batch property. -
Question 307:
DRAG DROP
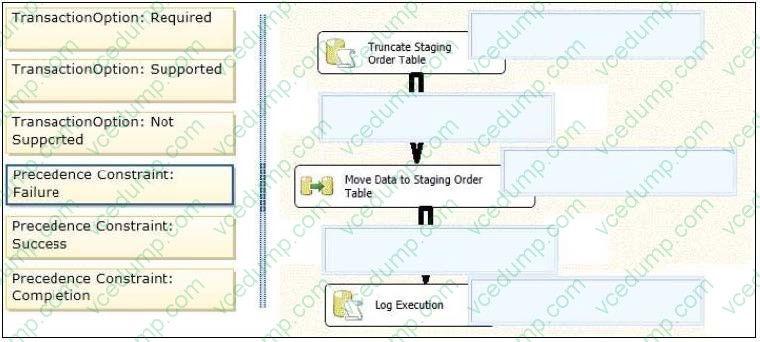
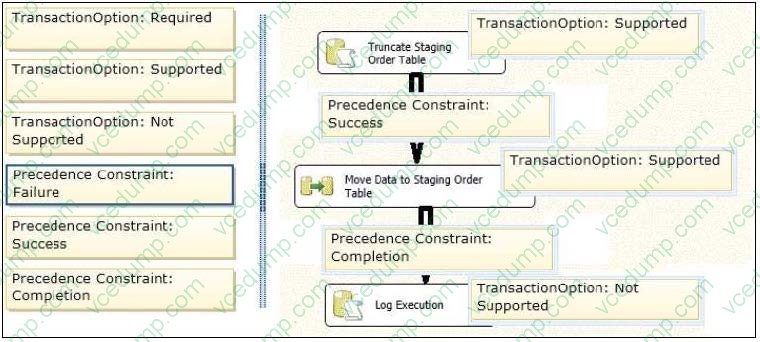
You are designing a SQL Server Integration Services (SSIS) package. The package moves order-related data to a staging table named Order. Every night the staging data is truncated and then all the recent orders from the online store
database are inserted into the staging
table.
Your package must meet the following requirements:
If the truncate operation fails, the package execution must stop and report an error.
If the Data Flow task that moves the data to the staging table fails, the entire refresh operation must be rolled back.
For auditing purposes, a log entry must be entered in a SQL log table after each execution of the Data Flow task.
The TransactionOption property for the package is set to Required.
You need to design the package to meet the requirements.
How should you design the control flow for the package? (To answer, drag the appropriate setting from the list of settings to the correct location or locations in the answer area.)
Select and Place:
-
Question 308:
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of thescenario is exactly the same in each question in this series.
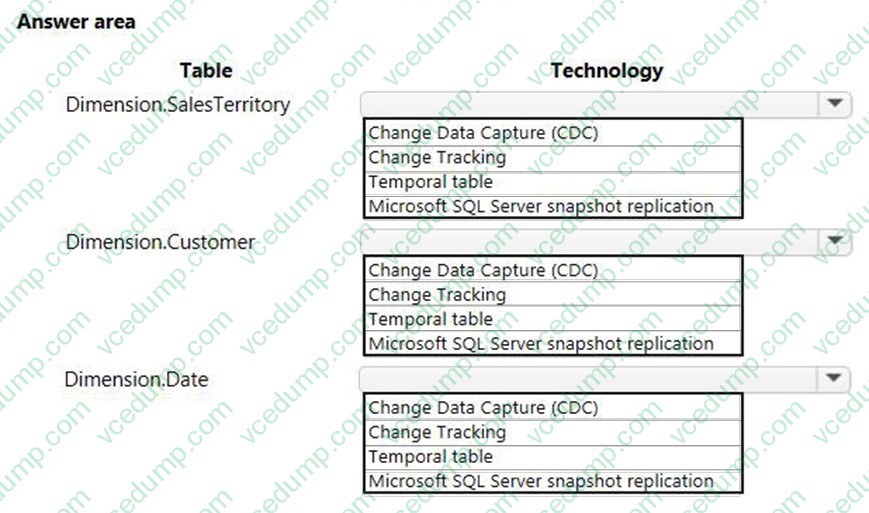
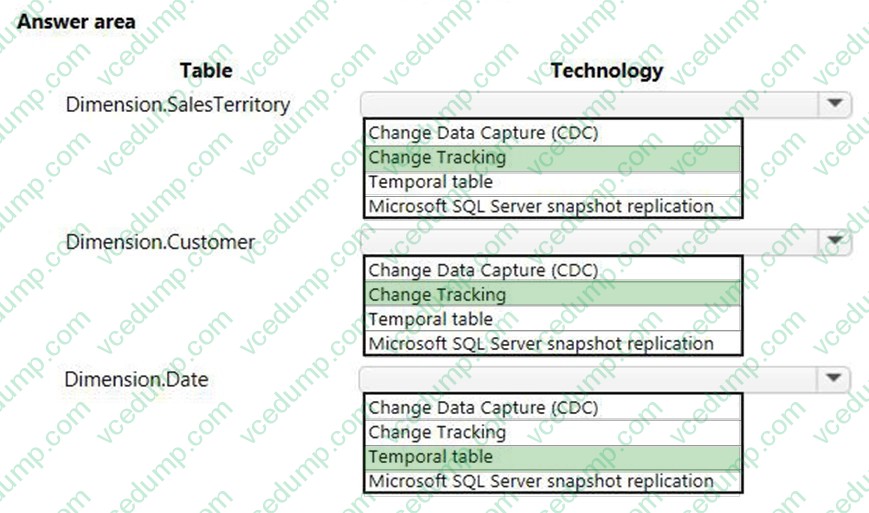
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The Fact.Order table is optimized for weekly reporting, but the company wants to change it to daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
Implement table partitioning to improve the manageability of the data warehouse and to avoid the need to repopulate all transactional data each night. Use a partitioning strategy that is as granular as possible.
Partition the Fact.Order table and retain a total of seven years of data.
Partition the Fact.Ticket table and retain seven years of data. At the end of each month, the partition structure must apply a sliding window strategy to ensure that a new partition is available for the upcoming month, and that the oldest month of data is archived and removed.
Optimize data loading for the Dimension.SalesTerritory, Dimension.Customer, and Dimension.Date tables.
Incrementally load all tables in the database and ensure that all incremental changes are processed.
Maximize the performance during the data loading process for the Fact.Order partition.
Ensure that historical data remains online and available for querying.
Reduce ongoing storage costs while maintaining query performance for current data.
You are not permitted to make changes to the client applications.
You need to configure data loading for the tables.
Which data loading technology should you use for each table? To answer, select the appropriate options in the answer area.
Hot Area:
-
Question 309:
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while
others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You configure a new matching policy Master Data Services (MDS) as shown in the following exhibit.
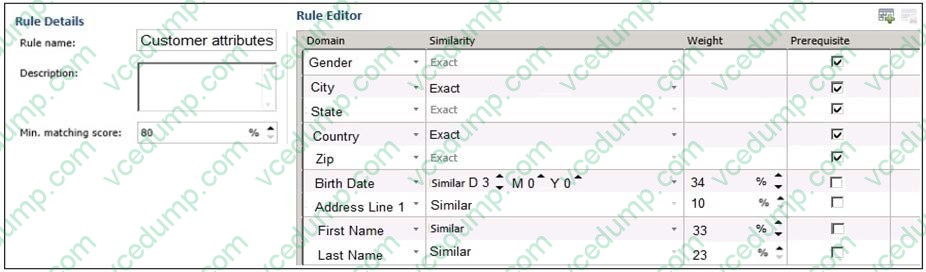
You review the Matching Results of the policy and find that the number of new values matches the new values.
You verify that the data contains multiple records that have similar address values, and you expect some of the records to match.
You need to increase the likelihood that the records will match when they have similar address values.
Solution: You decrease the relative weights for Address Line 1 of the matching policy.
Does this meet the goal?
A. Yes
B. No -
Question 310:
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is
exactly the same in each question in this series.
You have a Microsoft SQL Server data warehouse instance that supports several client applications.
The data warehouse includes the following tables: Dimension.SalesTerritory, Dimension.Customer, Dimension.Date, Fact.Ticket, and Fact.Order. The Dimension.SalesTerritory and Dimension.Customer tables are frequently updated. The
Fact.Order table is optimized for weekly reporting, but the company wants to change it daily. The Fact.Order table is loaded by using an ETL process. Indexes have been added to the table over time, but the presence of these indexes slows
data loading.
All data in the data warehouse is stored on a shared SAN. All tables are in a database named DB1. You have a second database named DB2 that contains copies of production data for a development environment. The data warehouse has
grown and the cost of storage has increased. Data older than one year is accessed infrequently and is considered historical.
You have the following requirements:
You are not permitted to make changes to the client applications.
You need to optimize the storage for the data warehouse.
What change should you make?
A. Partition the Fact.Order table, and move historical data to new filegroups on lower-cost storage.
B. Create new tables on lower-cost storage, move the historical data to the new tables, and then shrink the database.
C. Remove the historical data from the database to leave available space for new data.
D. Move historical data to new tables on lower-cost storage.

Related Exams:
-
62-193
Technology Literacy for Educators -
70-243
Administering and Deploying System Center 2012 Configuration Manager -
70-355
Universal Windows Platform – App Data, Services, and Coding Patterns -
77-420
Excel 2013 -
77-427
Excel 2013 Expert Part One -
77-725
Word 2016 Core Document Creation, Collaboration and Communication -
77-726
Word 2016 Expert Creating Documents for Effective Communication -
77-727
Excel 2016 Core Data Analysis, Manipulation, and Presentation -
77-728
Excel 2016 Expert: Interpreting Data for Insights -
77-731
Outlook 2016 Core Communication, Collaboration and Email Skills
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Microsoft exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your 70-767 exam preparations and Microsoft certification application, do not hesitate to visit our Vcedump.com to find your solutions here.