DATABRICKS-MACHINE-LEARNING-PROFESSIONAL Exam Details
-
Exam Code
:DATABRICKS-MACHINE-LEARNING-PROFESSIONAL -
Exam Name
:Databricks Certified Machine Learning Professional -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:60 Q&As -
Last Updated
:Jul 09, 2026
Databricks DATABRICKS-MACHINE-LEARNING-PROFESSIONAL Online Questions & Answers
-
Question 31:
A data scientist has created a Python function compute_features that returns a Spark DataFrame with the following schema

The resulting DataFrame is assigned to the features_df variable. The data scientist wants to create a Feature Store table using features_df. Which of the following code blocks can they use to create and populate the Feature Store table using the Feature Store Client fs?
A. Option A
B. Option B
C. Option C
D. Option D
E. Option E -
Question 32:
A machine learning engineer wants to move their model version model_version for the MLflow Model Registry model model from the Staging stage to the Production stage using MLflow Client client. Which of the following code blocks can they use to accomplish the task?
A. Option A
B. Option B
C. Option C
D. Option D
E. Option E -
Question 33:
A machine learning engineer wants to log feature importance data from a CSV file at path importance_path with an MLflow run for model model. Which of the following code blocks will accomplish this task inside of an existing MLflow run block?
A. Option A
B. Option B
C. Option C
D. Option D
E. Option E -
Question 34:
A machine learning engineer is in the process of implementing a concept drift monitoring solution. They are planning to use the following steps:
1.
Deploy a model to production and compute predicted values
2.
Obtain the observed (actual) label values
3.
_____
4.
Run a statistical test to determine if there are changes over time Which of the following should be completed as Step #3?
A. Obtain the observed values (actual) feature values
B. Measure the latency of the prediction time
C. Retrain the model
D. None of these should be completed as Step #3
E. Compute the evaluation metric using the observed and predicted values -
Question 35:
A data scientist is using MLflow to track their machine learning experiment. As a part of each MLflow run, they are performing hyperparameter tuning. The data scientist would like to have one parent run for the tuning process with a child run for each unique combination of hyperparameter values.
They are using the following code block:
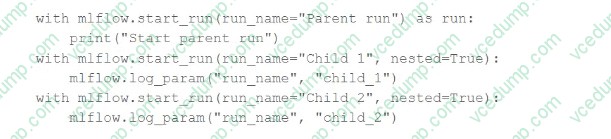
The code block is not nesting the runs in MLflow as they expected.
Which of the following changes does the data scientist need to make to the above code block so that it successfully nests the child runs under the parent run in MLflow?
A. Indent the child run blocks within the parent run block
B. Add the nested=True argument to the parent run
C. Remove the nested=True argument from the child runs
D. Provide the same name to the run_name parameter for all three run blocks
E. Add the nested=True argument to the parent run and remove the nested=True arguments from the child runs -
Question 36:
Which of the following MLflow operations can be used to automatically calculate and log a Shapley feature importance plot?
A. mlflow.shap.log_explanation
B. None of these operations can accomplish the task.
C. mlflow.shap
D. mlflow.log_figure
E. client.log_artifact -
Question 37:
A machine learning engineer needs to deliver predictions of a machine learning model in real-time. However, the feature values needed for computing the predictions are available one week before the query time. Which of the following is a benefit of using a batch serving deployment in this scenario rather than a real-time serving deployment where predictions are computed at query time?
A. Batch serving has built-in capabilities in Databricks Machine Learning
B. There is no advantage to using batch serving deployments over real-time serving deployments
C. Computing predictions in real-time provides more up-to-date results
D. Testing is not possible in real-time serving deployments
E. Querying stored predictions can be faster than computing predictions in real-time -
Question 38:
A data scientist has computed updated feature values for all primary key values stored in the Feature Store table features. In addition, feature values for some new primary key values have also been computed. The updated feature values are
stored in the DataFrame features_df. They want to replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client fs?
A. Option A
B. Option B
C. Option C
D. Option D
E. Option E -
Question 39:
A data scientist has developed a scikit-learn model sklearn_model and they want to log the model using MLflow.
They write the following incomplete code block:
image14
Which of the following lines of code can be used to fill in the blank so the code block can successfully complete the task?
A. mlflow.spark.track_model(sklearn_model, "model")
B. mlflow.sklearn.log_model(sklearn_model, "model")
C. mlflow.spark.log_model(sklearn_model, "model")
D. mlflow.sklearn.load_model("model")
E. mlflow.sklearn.track_model(sklearn_model, "model") -
Question 40:
A data scientist set up a machine learning pipeline to automatically log a data visualization with each run. They now want to view the visualizations in Databricks. Which of the following locations in Databricks will show these data visualizations?
A. The MLflow Model Registry Model page
B. The Artifacts section of the MLflow Experiment page
C. Logged data visualizations cannot be viewed in Databricks
D. The Artifacts section of the MLflow Run page
E. The Figures section of the MLflow Run page
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-MACHINE-LEARNING-PROFESSIONAL exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.