DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Exam Details
-
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER -
Exam Name
:Databricks Certified Data Engineer Professional -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:127 Q&As -
Last Updated
:Jul 15, 2026
Databricks DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Online Questions & Answers
-
Question 71:
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function will automatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected.
The function is displayed below with a blank:
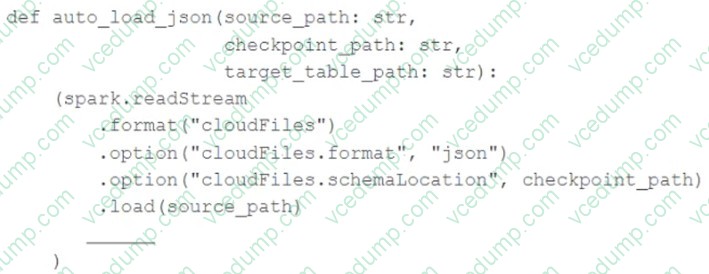
Which response correctly fills in the blank to meet the specified requirements?
A. Option A
B. Option B
C. Option C
D. Option D
E. Option E -
Question 72:
A team of data engineer are adding tables to a DLT pipeline that contain repetitive expectations for many of the same data quality checks.
One member of the team suggests reusing these data quality rules across all tables defined for this pipeline.
What approach would allow them to do this?
A. Maintain data quality rules in a Delta table outside of this pipeline's target schema, providing the schema name as a pipeline parameter.
B. Use global Python variables to make expectations visible across DLT notebooks included in the same pipeline.
C. Add data quality constraints to tables in this pipeline using an external job with access to pipeline configuration files.
D. Maintain data quality rules in a separate Databricks notebook that each DLT notebook of file. -
Question 73:
Which of the following technologies can be used to identify key areas of text when parsing Spark Driver log4j output?
A. Regex
B. Julia
C. pyspsark.ml.feature
D. Scala Datasets
E. C++ -
Question 74:
A Data engineer wants to run unit's tests using common Python testing frameworks on python functions defined across several Databricks notebooks currently used in production. How can the data engineer run unit tests against function that work with data in production?
A. Run unit tests against non-production data that closely mirrors production
B. Define and unit test functions using Files in Repos
C. Define units test and functions within the same notebook
D. Define and import unit test functions from a separate Databricks notebook -
Question 75:
A table nameduser_ltvis being used to create a view that will be used by data analysts on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
Theuser_ltvtable has the following schema:
email STRING, age INT, ltv INT
The following view definition is executed:
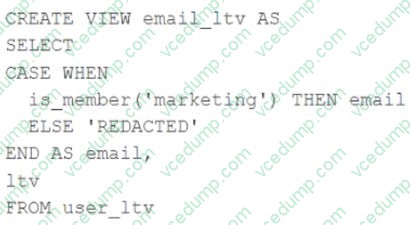
An analyst who is not a member of the marketing group executes the following query:
SELECT * FROM email_ltv
Which statement describes the results returned by this query?
A. Three columns will be returned, but one column will be named "redacted" and contain only null values.
B. Only the email and itv columns will be returned; the email column will contain all null values.
C. The email and ltv columns will be returned with the values in user itv.
D. The email, age. and ltv columns will be returned with the values in user ltv.
E. Only the email and ltv columns will be returned; the email column will contain the string "REDACTED" in each row. -
Question 76:
A Delta Lake table representing metadata about content posts from users has the following schema:
user_id LONG post_text STRING post_id STRING longitude FLOAT latitude FLOAT post_time TIMESTAMP date DATE
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
A. date
B. user_id
C. post_id
D. post_time -
Question 77:
Which Python variable contains a list of directories to be searched when trying to locate required modules?
A. importlib.resource path
B. ,sys.path
C. os-path
D. pypi.path
E. pylib.source -
Question 78:
A junior member of the data engineering team is exploring the language interoperability of Databricks notebooks. The intended outcome of the below code is to register a view of all sales that occurred in countries on the continent of Africa that appear in thegeo_lookuptable.
Before executing the code, runningSHOWTABLESon the current database indicates the database contains only two tables:geo_lookupandsales.

Which statement correctly describes the outcome of executing these command cells in order in an interactive notebook?
A. Both commands will succeed. Executing show tables will show that countries at and sales at have been registered as views.
B. Cmd 1 will succeed. Cmd 2 will search all accessible databases for a table or view named countries af: if this entity exists, Cmd 2 will succeed.
C. Cmd 1 will succeed and Cmd 2 will fail, countries at will be a Python variable representing a PySpark DataFrame.
D. Both commands will fail. No new variables, tables, or views will be created.
E. Cmd 1 will succeed and Cmd 2 will fail, countries at will be a Python variable containing a list of strings. -
Question 79:
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on task A. If tasks A and B complete successfully but task C fails during a scheduled run, which statement describes the resulting state?
A. All logic expressed in the notebook associated with tasks A and B will have been successfully completed; some operations in task C may have completed successfully.
B. All logic expressed in the notebook associated with tasks A and B will have been successfully completed; any changes made in task C will be rolled back due to task failure.
C. All logic expressed in the notebook associated with task A will have been successfully completed; tasks B and C will not commit any changes because of stage failure.
D. Because all tasks are managed as a dependency graph, no changes will be committed to the Lakehouse until ail tasks have successfully been completed.
E. Unless all tasks complete successfully, no changes will be committed to the Lakehouse; because task C failed, all commits will be rolled back automatically. -
Question 80:
A junior developer complains that the code in their notebook isn't producing the correct results in the development environment. A shared screenshot reveals that while they're using a notebook versioned with Databricks Repos, they're using a personal branch that contains old logic. The desired branch nameddev-2.3.9is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
A. Use Repos to make a pull request use the Databricks REST API to update the current branch to dev-2.3.9
B. Use Repos to pull changes from the remote Git repository and select the dev-2.3.9 branch.
C. Use Repos to checkout the dev-2.3.9 branch and auto-resolve conflicts with the current branch
D. Merge all changes back to the main branch in the remote Git repository and clone the repo again
E. Use Repos to merge the current branch and the dev-2.3.9 branch, then make a pull request to sync with the remote repository
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.