DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Exam Details
-
Exam Code
:DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER -
Exam Name
:Databricks Certified Data Engineer Professional -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:127 Q&As -
Last Updated
:Jul 15, 2026
Databricks DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER Online Questions & Answers
-
Question 11:
What is the first of a Databricks Python notebook when viewed in a text editor?
A. %python
B. % Databricks notebook source
C. -- Databricks notebook source
D. //Databricks notebook source -
Question 12:
A data engineer is performing a join operating to combine values from a static userlookup table with a streaming DataFrame streamingDF. Which code block attempts to perform an invalid stream-static join?
A. userLookup.join(streamingDF, ["userid"], how="inner")
B. streamingDF.join(userLookup, ["user_id"], how="outer")
C. streamingDF.join(userLookup, ["user_id"], how="left")
D. streamingDF.join(userLookup, ["userid"], how="inner")
E. userLookup.join(streamingDF, ["user_id"], how="right") -
Question 13:
The following code has been migrated to a Databricks notebook from a legacy workload:
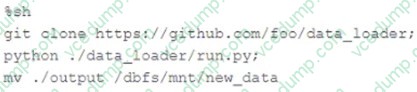
The code executes successfully and provides the logically correct results, however, it takes over 20 minutes to extract and load around 1 GB of data. Which statement is a possible explanation for this behavior?
A. %sh triggers a cluster restart to collect and install Git. Most of the latency is related to cluster startup time.
B. Instead of cloning, the code should use %sh pip install so that the Python code can get executed in parallel across all nodes in a cluster.
C. %sh does not distribute file moving operations; the final line of code should be updated to use %fs instead.
D. Python will always execute slower than Scala on Databricks. The run.py script should be refactored to Scala.
E. %sh executes shell code on the driver node. The code does not take advantage of the worker nodes or Databricks optimized Spark. -
Question 14:
All records from an Apache Kafka producer are being ingested into a single Delta Lake table with the following schema: key BINARY, value BINARY, topic STRING, partition LONG, offset LONG, timestamp LONG There are 5 unique topics being ingested. Only the "registration" topic contains Personal Identifiable Information (PII). The company wishes to restrict access to PII. The company also wishes to only retain records containing PII in this table for
14 days after initial ingestion. However, for non-PII information, it would like to retain these records indefinitely. Which of the following solutions meets the requirements?
A. All data should be deleted biweekly; Delta Lake's time travel functionality should be leveraged to maintain a history of non-PII information.
B. Data should be partitioned by the registration field, allowing ACLs and delete statements to be set for the PII directory.
C. Because the value field is stored as binary data, this information is not considered PII and no special precautions should be taken.
D. Separate object storage containers should be specified based on the partition field, allowing isolation at the storage level.
E. Data should be partitioned by the topic field, allowing ACLs and delete statements to leverage partition boundaries. -
Question 15:
The data governance team is reviewing code used for deleting records for compliance with GDPR. They note the following logic is used to delete records from the Delta Lake table namedusers.

Assuming thatuser_idis a unique identifying key and thatdelete_requestscontains all users that have requested deletion, which statement describes whether successfully executing the above logic guarantees that the records to be deleted are no longer accessible and why?
A. Yes; Delta Lake ACID guarantees provide assurance that the delete command succeeded fully and permanently purged these records.
B. No; the Delta cache may return records from previous versions of the table until the cluster is restarted.
C. Yes; the Delta cache immediately updates to reflect the latest data files recorded to disk.
D. No; the Delta Lake delete command only provides ACID guarantees when combined with the merge into command.
E. No; files containing deleted records may still be accessible with time travel until a vacuum command is used to remove invalidated data files. -
Question 16:
A junior data engineer has manually configured a series of jobs using the Databricks Jobs UI. Upon reviewing their work, the engineer realizes that they are listed as the "Owner" for each job. They attempt to transfer "Owner" privileges to the "DevOps" group, but cannot successfully accomplish this task.
Which statement explains what is preventing this privilege transfer?
A. Databricks jobs must have exactly one owner; "Owner" privileges cannot be assigned to a group.
B. The creator of a Databricks job will always have "Owner" privileges; this configuration cannot be changed.
C. Other than the default "admins" group, only individual users can be granted privileges on jobs.
D. A user can only transfer job ownership to a group if they are also a member of that group.
E. Only workspace administrators can grant "Owner" privileges to a group. -
Question 17:
The data engineer is using Spark's MEMORY_ONLY storage level. Which indicators should the data engineer look for in the spark UI's Storage tab to signal that a cached table is not performing optimally?
A. Size on Disk is> 0
B. The number of Cached Partitions> the number of Spark Partitions
C. The RDD Block Name included the '' annotation signaling failure to cache
D. On Heap Memory Usage is within 75% of off Heap Memory usage -
Question 18:
A data engineer has created a transactions Delta table on Databricks that should be used by the analytics team. The analytics team wants to use the table with another tool that requires Apache Iceberg format. What should the data engineer do?
A. Require the analytics team to use a tool that supports Delta table.
B. Enable uniform on the transactions table to 'iceberg' so that the table can be read as an Iceberg table.
C. Create an Iceberg copy of the transactions Delta table which can be used by the analytics team.
D. Convert the transactions Delta table to Iceberg and enable uniform so that the table can be read as a Delta table. -
Question 19:
A junior data engineer is working to implement logic for a Lakehouse table named silver_device_recordings. The source data contains 100 unique fields in a highly nested JSON structure.
The silver_device_recordings table will be used downstream for highly selective joins on a number of fields, and will also be leveraged by the machine learning team to filter on a handful of relevant fields, in total, 15 fields have been identified
that will often be used for filter and join logic.
The data engineer is trying to determine the best approach for dealing with these nested fields before declaring the table schema.
Which of the following accurately presents information about Delta Lake and Databricks that may Impact their decision-making process?
A. Because Delta Lake uses Parquet for data storage, Dremel encoding information for nesting can be directly referenced by the Delta transaction log.
B. Tungsten encoding used by Databricks is optimized for storing string data: newly-added native support for querying JSON strings means that string types are always most efficient.
C. Schema inference and evolution on Databricks ensure that inferred types will always accurately match the data types used by downstream systems.
D. By default Delta Lake collects statistics on the first 32 columns in a table; these statistics are leveraged for data skipping when executing selective queries. -
Question 20:
What is true for Delta Lake?
A. Views in the Lakehouse maintain a valid cache of the most recent versions of source tables at all times.
B. Delta Lake automatically collects statistics on the first 32 columns of each table, which are leveraged in data skipping based on query filters.
C. Z-ORDERcan only be applied to numeric values stored in Delta Lake tables.
D. Primary and foreign key constraints can be leveraged to ensure duplicate values are never entered into a dimension table.
Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.