ARA-C01 Exam Details
-
Exam Code
:ARA-C01 -
Exam Name
:SnowPro Advanced: Architect Certification (ARA-C01) -
Certification
:Snowflake Certifications -
Vendor
:Snowflake -
Total Questions
:65 Q&As -
Last Updated
:Jul 12, 2026
Snowflake ARA-C01 Online Questions & Answers
-
Question 61:
A company's daily Snowflake workload consists of a huge number of concurrent queries triggered between 9pm and 11pm. At the individual level, these queries are smaller statements that get completed within a short time period.
What configuration can the company's Architect implement to enhance the performance of this workload? (Choose two.)
A. Enable a multi-clustered virtual warehouse in maximized mode during the workload duration.
B. Set the MAX_CONCURRENCY_LEVEL to a higher value than its default value of 8 at the virtual warehouse level.
C. Increase the size of the virtual warehouse to size X-Large.
D. Reduce the amount of data that is being processed through this workload.
E. Set the connection timeout to a higher value than its default. -
Question 62:
A user has the appropriate privilege to see unmasked data in a column.
If the user loads this column data into another column that does not have a masking policy, what will occur?
A. Unmasked data will be loaded in the new column.
B. Masked data will be loaded into the new column.
C. Unmasked data will be loaded into the new column but only users with the appropriate privileges will be able to see the unmasked data.
D. Unmasked data will be loaded into the new column and no users will be able to see the unmasked data. -
Question 63:
A company has several sites in different regions from which the company wants to ingest data.
Which of the following will enable this type of data ingestion?
A. The company must have a Snowflake account in each cloud region to be able to ingest data to that account.
B. The company must replicate data between Snowflake accounts.
C. The company should provision a reader account to each site and ingest the data through the reader accounts.
D. The company should use a storage integration for the external stage. -
Question 64:
A healthcare company wants to share data with a medical institute. The institute is running a Standard edition of Snowflake; the healthcare company is running a Business Critical edition.
How can this data be shared?
A. The healthcare company will need to change the institute's Snowflake edition in the accounts panel.
B. By default, sharing is supported from a Business Critical Snowflake edition to a Standard edition.
C. Contact Snowflake and they will execute the share request for the healthcare company.
D. Set the share_restriction parameter on the shared object to false. -
Question 65:
A table contains five columns and it has millions of records. The cardinality distribution of the columns is shown below:
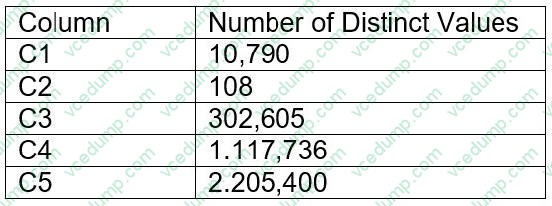
Column C4 and C5 are mostly used by SELECT queries in the GROUP BY and ORDER BY clauses. Whereas columns C1, C2 and C3 are heavily used in filter and join conditions of SELECT queries.
The Architect must design a clustering key for this table to improve the query performance.
Based on Snowflake recommendations, how should the clustering key columns be ordered while defining the multi-column clustering key?
A. C5, C4, C2
B. C3, C4, C5
C. C1, C3, C2
D. C2, C1, C3
Related Exams:
-
ADA-C01
SnowPro Advanced: Administrator Certification (ADA-C01) -
ARA-C01
SnowPro Advanced: Architect Certification (ARA-C01) -
COF-C02
SnowPro Core Certification (COF-C02) -
COF-R02
SnowPro Core Recertification (COF-R02) -
DAA-C01
SnowPro Advanced: Data Analyst (DAA-C01) -
DSA-C02
SnowPro Advanced: Data Scientist Certification (DSA-C02) -
SOL-C01
SnowPro Associate: Platform Certification
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Snowflake exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your ARA-C01 exam preparations and Snowflake certification application, do not hesitate to visit our Vcedump.com to find your solutions here.