Exam Details
Exam Code
:APACHE-HADOOP-DEVELOPERExam Name
:Hadoop 2.0 Certification for Pig and Hive DeveloperCertification
:Hortonworks CertificationsVendor
:HortonworksTotal Questions
:60 Q&AsLast Updated
:Jun 27, 2025
Hortonworks Hortonworks Certifications APACHE-HADOOP-DEVELOPER Questions & Answers
-
Question 81:
What data does a Reducer reduce method process?
A. All the data in a single input file.
B. All data produced by a single mapper.
C. All data for a given key, regardless of which mapper(s) produced it.
D. All data for a given value, regardless of which mapper(s) produced it.
-
Question 82:
You are developing a MapReduce job for sales reporting. The mapper will process input keys representing the year (IntWritable) and input values representing product indentifies (Text).
Indentify what determines the data types used by the Mapper for a given job.
A. The key and value types specified in the JobConf.setMapInputKeyClass and JobConf.setMapInputValuesClass methods
B. The data types specified in HADOOP_MAP_DATATYPES environment variable
C. The mapper-specification.xml file submitted with the job determine the mapper's input key and value types.
D. The InputFormat used by the job determines the mapper's input key and value types.
-
Question 83:
Analyze each scenario below and indentify which best describes the behavior of the default partitioner?
A. The default partitioner assigns key-values pairs to reduces based on an internal random number generator.
B. The default partitioner implements a round-robin strategy, shuffling the key-value pairs to each reducer in turn. This ensures an event partition of the key space.
C. The default partitioner computes the hash of the key. Hash values between specific ranges are associated with different buckets, and each bucket is assigned to a specific reducer.
D. The default partitioner computes the hash of the key and divides that valule modulo the number of reducers. The result determines the reducer assigned to process the key-value pair.
E. The default partitioner computes the hash of the value and takes the mod of that value with the number of reducers. The result determines the reducer assigned to process the key-value pair.
-
Question 84:
You want to understand more about how users browse your public website, such as which pages they visit prior to placing an order. You have a farm of 200 web servers hosting your website. How will you gather this data for your analysis?
A. Ingest the server web logs into HDFS using Flume.
B. Write a MapReduce job, with the web servers for mappers, and the Hadoop cluster nodes for reduces.
C. Import all users' clicks from your OLTP databases into Hadoop, using Sqoop.
D. Channel these clickstreams inot Hadoop using Hadoop Streaming.
E. Sample the weblogs from the web servers, copying them into Hadoop using curl.
-
Question 85:
Which two of the following are true about this trivial Pig program' (choose Two)

A. The contents of myfile appear on stdout
B. Pig assumes the contents of myfile are comma delimited
C. ABC has a schema associated with it
D. myfile is read from the user's home directory in HDFS
-
Question 86:
Review the following andapos;dataandapos; file and Pig code.
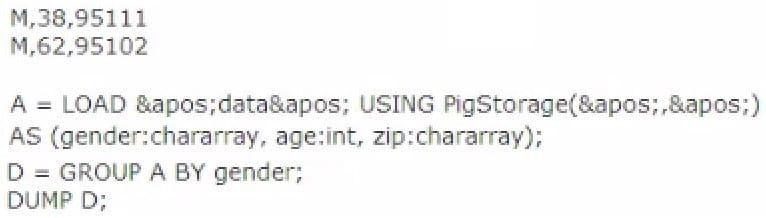
Which one of the following statements is true?
A. The Output Of the DUMP D command IS (M,{(M,62.95102),(M,38,95111)})
B. The output of the dump d command is (M, {(38,95in),(62,95i02)})
C. The code executes successfully but there is not output because the D relation is empty
D. The code does not execute successfully because D is not a valid relation
-
Question 87:
What does the following command do? register andapos;/piggyban):/pig-files.jarandapos;;
A. Invokes the user-defined functions contained in the jar file
B. Assigns a name to a user-defined function or streaming command
C. Transforms Pig user-defined functions into a format that Hive can accept
D. Specifies the location of the JAR file containing the user-defined functions
-
Question 88:
What is the term for the process of moving map outputs to the reducers?
A. Reducing
B. Combining
C. Partitioning
D. Shuffling and sorting
-
Question 89:
All keys used for intermediate output from mappers must:
A. Implement a splittable compression algorithm.
B. Be a subclass of FileInputFormat.
C. Implement WritableComparable.
D. Override isSplitable.
E. Implement a comparator for speedy sorting.
-
Question 90:
MapReduce v2 (MRv2/YARN) is designed to address which two issues?
A. Single point of failure in the NameNode.
B. Resource pressure on the JobTracker.
C. HDFS latency.
D. Ability to run frameworks other than MapReduce, such as MPI.
E. Reduce complexity of the MapReduce APIs.
F. Standardize on a single MapReduce API.
Related Exams:
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Hortonworks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your APACHE-HADOOP-DEVELOPER exam preparations and Hortonworks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.