Exam Details
Exam Code
:DS-200Exam Name
:Data Science EssentialsCertification
:Cloudera CertificationsVendor
:ClouderaTotal Questions
:60 Q&AsLast Updated
:Jul 08, 2025
Cloudera Cloudera Certifications DS-200 Questions & Answers
-
Question 51:
You have user profile records in an OLTP database that you want to join with web server logs which you have already ingested into HDFS. What is the best way to acquire the user profile for use in HDFS?
A. Ingest with Hadoop streaming
B. Ingest with Apache Flume
C. Ingest using Hive's LOAD DATA command
D. Ingest using Sqoop
E. Ingest using Pig's LOAD command
-
Question 52:
You are building a system to perform outlier detection for a large online retailer. You need to build a system to detect if the total dollar value of sales are outside the norm for each U.S. state, as determined from the physical location of the buyer for each purchase. The retailer's data sources are scattered across multiple systems and databases and are unorganized with little coordination or shared data or keys between the various data sources.
Below are the sources of data available to you. Determine which three will give you the smallest set of data sources but still allow you to implement the outlier detector by state.
A. Database of employees that Includes only the employee ID, start date, and department
B. Database of users that contains only their user ID, name, and a list of every Item the user has viewed
C. Transaction log that contains only basket ID, basket amount, time of sale completion, and a session ID
D. Database of user sessions that includes only session ID, corresponding user ID, and the corresponding IP address
E. External database mapping IP addresses to geographic locations
F. Database of items that includes only the item name, item ID, and warehouse location
G. Database of shipments that includes only the basket ID, shipment address, shipment date, and shipment method
-
Question 53:
How can the naiveté of the naive Bayes classifier be advantageous?
A. It does not require you to make strong assumptions about the data because it is a non- parametric
B. It significantly reduces the size of the parameter space, thus reducing the risk of over fitting
C. It allows you to reduce bias with no tradeoff in variance
D. It guarantees convergence of the estimator
-
Question 54:
What are two defining features of RMSE (root-mean square error or root-mean-square deviation)?
A. It is sensitive to outliers
B. It is the mean value of recommendations of the K-equal partitions in the input data
C. It is the square of the median value of the error where error is the difference between predicted rating and actual ratings
D. It is appropriate for numeric data
E. It considers the order of recommendations
-
Question 55:
Consider the following sample from a distribution that contains a continuous X and label Y that is either A or B:
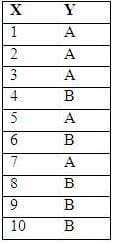
Which is the best cut point for X if you want to discretize these values into two buckets in a way that minimizes the sum of chi-square values?
A. X 8
B. X 6
C. X 5
D. X 4
E. X 2
-
Question 56:
Consider the following sample from a distribution that contains a continuous X and label Y that is either A or B:
Which is the best choice of cut points for X if you want to discretize these values into three buckets that minimizes the sum of chi-square values?
A. X 5 and X 8
B. X 4 and X 6
C. X 3 and X 8
D. X 3 and X 6
E. X 2 and X 9
-
Question 57:
You want to understand more about how users browse your public website. For example, you war know which pages they visit prior to placing an order. You have a server farm of 200 web server hosting your website. Which is the most efficient process to gather these web servers access logs into your Hadoop cluster for analysis?
A. Sample the web server logs web servers and copy them into HDFS using curl
B. Channel these click streams into Hadoop using Hadoop Streaming
C. Write a MapReduce job with the web servers for mappers and the Hadoop cluster nodes for reducers
D. Import all user clicks from your OLTP databases Into Hadoop using Sqoop
E. Ingest the server web logs into HDFS using Flume
-
Question 58:
You have a large file of N records (one per line), and want to randomly sample 10% them. You have two
functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1] random_permotation (M)
generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file: If random_uniform () < 0.1; Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method will have the best runtime performance?
A. Method A
B. Method B
C. Method C
-
Question 59:
You have a large file of N records (one per line), and want to randomly sample 10% them. You have two
functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1] random_permotation (M)
generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file: If random_uniform () < 0.1; Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method requires the most RAM?
A. Method A
B. Method B
C. Method C
-
Question 60:
You have a large file of N records (one per line), and want to randomly sample 10% them. You have two
functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1] random_permotation (M)
generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file: If random_uniform () < 0.1; Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method might introduce unexpected correlations?
A. Method A
B. Method B
C. Method C
Related Exams:
CCA-175
Cloudera Certified Administrator Spark and Hadoop DeveloperCCA-410
Cloudera Certified Administrator for Apache Hadoop CDH4CCA-470
Cloudera Certified Administrator for Apache Hadoop CDH4 Upgrade Exam (CCAH)CCA-500
Cloudera Certified Administrator for Apache Hadoop (CCAH)CCA-505
Cloudera Certified Administrator for Apache Hadoop (CCAH) CDH5 Upgrade ExamCCB-400
Cloudera Certified Specialist in Apache HBaseCCD-410
Cloudera Certified Developer for Apache Hadoop (CCDH)CCD-470
Cloudera Certified Developer for Apache Hadoop CDH4 Upgrade (CCDH)
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Cloudera exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DS-200 exam preparations and Cloudera certification application, do not hesitate to visit our Vcedump.com to find your solutions here.