Exam Details
Exam Code
:PROFESSIONAL-MACHINE-LEARNING-ENGINEERExam Name
:Professional Machine Learning EngineerCertification
:Google CertificationsVendor
:GoogleTotal Questions
:282 Q&AsLast Updated
:Jul 15, 2025
Google Google Certifications PROFESSIONAL-MACHINE-LEARNING-ENGINEER Questions & Answers
-
Question 21:
You work for the AI team of an automobile company, and you are developing a visual defect detection model using TensorFlow and Keras. To improve your model performance, you want to incorporate some image augmentation functions such as translation, cropping, and contrast tweaking. You randomly apply these functions to each training batch. You want to optimize your data processing pipeline for run time and compute resources utilization. What should you do?
A. Embed the augmentation functions dynamically in the tf.Data pipeline.
B. Embed the augmentation functions dynamically as part of Keras generators.
C. Use Dataflow to create all possible augmentations, and store them as TFRecords.
D. Use Dataflow to create the augmentations dynamically per training run, and stage them as TFRecords.
-
Question 22:
You are the Director of Data Science at a large company, and your Data Science team has recently begun using the Kubeflow Pipelines SDK to orchestrate their training pipelines. Your team is struggling to integrate their custom Python code into the Kubeflow Pipelines SDK. How should you instruct them to proceed in order to quickly integrate their code with the Kubeflow Pipelines SDK?
A. Use the func_to_container_op function to create custom components from the Python code.
B. Use the predefined components available in the Kubeflow Pipelines SDK to access Dataproc, and run the custom code there.
C. Package the custom Python code into Docker containers, and use the load_component_from_file function to import the containers into the pipeline.
D. Deploy the custom Python code to Cloud Functions, and use Kubeflow Pipelines to trigger the Cloud Function.
-
Question 23:
You have recently created a proof-of-concept (POC) deep learning model. You are satisfied with the overall architecture, but you need to determine the value for a couple of hyperparameters. You want to perform hyperparameter tuning on
Vertex AI to determine both the appropriate embedding dimension for a categorical feature used by your model and the optimal learning rate. You configure the following settings:
? For the embedding dimension, you set the type to INTEGER with a minValue of 16 and maxValue of 64.
? For the learning rate, you set the type to DOUBLE with a minValue of 10e-05 and maxValue of 10e-02.
You are using the default Bayesian optimization tuning algorithm, and you want to maximize model accuracy. Training time is not a concern. How should you set the hyperparameter scaling for each hyperparameter and the maxParallelTrials?
A. Use UNIT_LINEAR_SCALE for the embedding dimension, UNIT_LOG_SCALE for the learning rate, and a large number of parallel trials.
B. Use UNIT_LINEAR_SCALE for the embedding dimension, UNIT_LOG_SCALE for the learning rate, and a small number of parallel trials.
C. Use UNIT_LOG_SCALE for the embedding dimension, UNIT_LINEAR_SCALE for the learning rate, and a large number of parallel trials.
D. Use UNIT_LOG_SCALE for the embedding dimension, UNIT_LINEAR_SCALE for the learning rate, and a small number of parallel trials.
-
Question 24:
You work on a data science team at a bank and are creating an ML model to predict loan default risk. You have collected and cleaned hundreds of millions of records worth of training data in a BigQuery table, and you now want to develop and compare multiple models on this data using TensorFlow and Vertex AI. You want to minimize any bottlenecks during the data ingestion state while considering scalability. What should you do?
A. Use the BigQuery client library to load data into a dataframe, and use tf.data.Dataset.from_tensor_slices() to read it.
B. Export data to CSV files in Cloud Storage, and use tf.data.TextLineDataset() to read them.
C. Convert the data into TFRecords, and use tf.data.TFRecordDataset() to read them.
D. Use TensorFlow I/O's BigQuery Reader to directly read the data.
-
Question 25:
You are an ML engineer at a mobile gaming company. A data scientist on your team recently trained a TensorFlow model, and you are responsible for deploying this model into a mobile application. You discover that the inference latency of the current model doesn't meet production requirements. You need to reduce the inference time by 50%, and you are willing to accept a small decrease in model accuracy in order to reach the latency requirement. Without training a new model, which model optimization technique for reducing latency should you try first?
A. Weight pruning
B. Dynamic range quantization
C. Model distillation
D. Dimensionality reduction
-
Question 26:
You have been asked to productionize a proof-of-concept ML model built using Keras. The model was trained in a Jupyter notebook on a data scientist's local machine. The notebook contains a cell that performs data validation and a cell that performs model analysis. You need to orchestrate the steps contained in the notebook and automate the execution of these steps for weekly retraining. You expect much more training data in the future. You want your solution to take advantage of managed services while minimizing cost. What should you do?
A. Move the Jupyter notebook to a Notebooks instance on the largest N2 machine type, and schedule the execution of the steps in the Notebooks instance using Cloud Scheduler.
B. Write the code as a TensorFlow Extended (TFX) pipeline orchestrated with Vertex AI Pipelines. Use standard TFX components for data validation and model analysis, and use Vertex AI Pipelines for model retraining.
C. Rewrite the steps in the Jupyter notebook as an Apache Spark job, and schedule the execution of the job on ephemeral Dataproc clusters using Cloud Scheduler.
D. Extract the steps contained in the Jupyter notebook as Python scripts, wrap each script in an Apache Airflow BashOperator, and run the resulting directed acyclic graph (DAG) in Cloud Composer.
-
Question 27:
You are working on a system log anomaly detection model for a cybersecurity organization. You have developed the model using TensorFlow, and you plan to use it for real-time prediction. You need to create a Dataflow pipeline to ingest data via Pub/Sub and write the results to BigQuery. You want to minimize the serving latency as much as possible. What should you do?
A. Containerize the model prediction logic in Cloud Run, which is invoked by Dataflow.
B. Load the model directly into the Dataflow job as a dependency, and use it for prediction.
C. Deploy the model to a Vertex AI endpoint, and invoke this endpoint in the Dataflow job.
D. Deploy the model in a TFServing container on Google Kubernetes Engine, and invoke it in the Dataflow job.
-
Question 28:
You are an ML engineer on an agricultural research team working on a crop disease detection tool to detect leaf rust spots in images of crops to determine the presence of a disease. These spots, which can vary in shape and size, are correlated to the severity of the disease. You want to develop a solution that predicts the presence and severity of the disease with high accuracy. What should you do?
A. Create an object detection model that can localize the rust spots.
B. Develop an image segmentation ML model to locate the boundaries of the rust spots.
C. Develop a template matching algorithm using traditional computer vision libraries.
D. Develop an image classification ML model to predict the presence of the disease.
-
Question 29:
While performing exploratory data analysis on a dataset, you find that an important categorical feature has 5% null values. You want to minimize the bias that could result from the missing values. How should you handle the missing values?
A. Remove the rows with missing values, and upsample your dataset by 5%.
B. Replace the missing values with the feature's mean.
C. Replace the missing values with a placeholder category indicating a missing value.
D. Move the rows with missing values to your validation dataset.
-
Question 30:
You are training an object detection model using a Cloud TPU v2. Training time is taking longer than expected. Based on this simplified trace obtained with a Cloud TPU profile, what action should you take to decrease training time in a cost-efficient way?
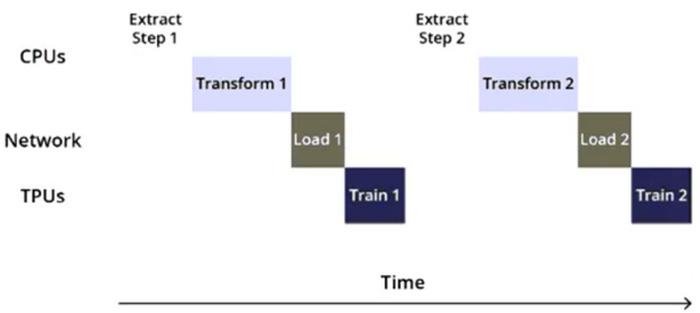
A. Move from Cloud TPU v2 to Cloud TPU v3 and increase batch size.
B. Move from Cloud TPU v2 to 8 NVIDIA V100 GPUs and increase batch size.
C. Rewrite your input function to resize and reshape the input images.
D. Rewrite your input function using parallel reads, parallel processing, and prefetch.
Related Exams:
ADWORDS-DISPLAY
Google AdWords: Display AdvertisingADWORDS-FUNDAMENTALS
Google AdWords: FundamentalsADWORDS-MOBILE
Google AdWords: Mobile AdvertisingADWORDS-REPORTING
Google AdWords: ReportingADWORDS-SEARCH
Google AdWords: Search AdvertisingADWORDS-SHOPPING
Google AdWords: Shopping AdvertisingADWORDS-VIDEO
Google AdWords: Video AdvertisingAPIGEE-API-ENGINEER
Apigee Certified API EngineerASSOCIATE-ANDROID-DEVELOPER
Associate Android Developer (Kotlin and Java)ASSOCIATE-CLOUD-ENGINEER
Associate Cloud Engineer
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Google exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your PROFESSIONAL-MACHINE-LEARNING-ENGINEER exam preparations and Google certification application, do not hesitate to visit our Vcedump.com to find your solutions here.