PROFESSIONAL-MACHINE-LEARNING-ENGINEER Exam Details
-
Exam Code
:PROFESSIONAL-MACHINE-LEARNING-ENGINEER -
Exam Name
:Professional Machine Learning Engineer -
Certification
:Google Certifications -
Vendor
:Google -
Total Questions
:291 Q&As -
Last Updated
:May 24, 2026
Google PROFESSIONAL-MACHINE-LEARNING-ENGINEER Online Questions & Answers
-
Question 181:
One of your models is trained using data provided by a third-party data broker. The data broker does not reliably notify you of formatting changes in the data. You want to make your model training pipeline more robust to issues like this. What should you do?
A. Use TensorFlow Data Validation to detect and flag schema anomalies.
B. Use TensorFlow Transform to create a preprocessing component that will normalize data to the expected distribution, and replace values that don't match the schema with 0.
C. Use tf.math to analyze the data, compute summary statistics, and flag statistical anomalies.
D. Use custom TensorFlow functions at the start of your model training to detect and flag known formatting errors. -
Question 182:
Your task is classify if a company logo is present on an image. You found out that 96% of a data does not include a logo. You are dealing with data imbalance problem. Which metric do you use to evaluate to model?
A. F1 Score
B. RMSE
C. F Score with higher precision weighting than recall
D. F Score with higher recall weighted than precision -
Question 183:
You work for a large social network service provider whose users post articles and discuss news. Millions of comments are posted online each day, and more than 200 human moderators constantly review comments and flag those that are inappropriate. Your team is building an ML model to help human moderators check content on the platform. The model scores each comment and flags suspicious comments to be reviewed by a human. Which metric(s) should you use to monitor the model's performance?
A. Number of messages flagged by the model per minute
B. Number of messages flagged by the model per minute confirmed as being inappropriate by humans.
C. Precision and recall estimates based on a random sample of 0.1% of raw messages each minute sent to a human for review
D. Precision and recall estimates based on a sample of messages flagged by the model as potentially inappropriate each minute -
Question 184:
You work for a bank. You have created a custom model to predict whether a loan application should be flagged for human review. The input features are stored in a BigQuery table. The model is performing well, and you plan to deploy it to production. Due to compliance requirements the model must provide explanations for each prediction. You want to add this functionality to your model code with minimal effort and provide explanations that are as accurate as possible. What should you do?
A. Create an AutoML tabular model by using the BigQuery data with integrated Vertex Explainable AI.
B. Create a BigQuery ML deep neural network model and use the ML.EXPLAIN_PREDICT method with the num_integral_steps parameter.
C. Upload the custom model to Vertex AI Model Registry and configure feature-based attribution by using sampled Shapley with input baselines.
D. Update the custom serving container to include sampled Shapley-based explanations in the prediction outputs. -
Question 185:
You are building an ML model to detect anomalies in real-time sensor data. You will use Pub/Sub to handle incoming requests. You want to store the results for analytics and visualization. How should you configure the pipeline?
A. 1 = Dataflow, 2 = AI Platform, 3 = BigQuery
B. 1 = DataProc, 2 = AutoML, 3 = Cloud Bigtable
C. 1 = BigQuery, 2 = AutoML, 3 = Cloud Functions
D. 1 = BigQuery, 2 = AI Platform, 3 = Cloud Storage -
Question 186:
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (PII) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?
A. 1= Dataflow, 2= BigQuery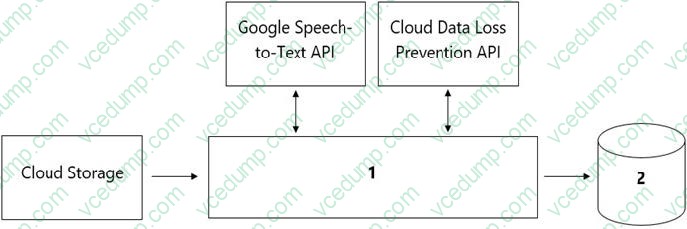
B. 1 = Pub/Sub, 2= Datastore
C. 1 = Dataflow, 2 = Cloud SQL
D. 1 = Cloud Function, 2= Cloud SQL -
Question 187:
You recently deployed a model to a Vertex AI endpoint and set up online serving in Vertex AI Feature Store. You have configured a daily batch ingestion job to update your featurestore. During the batch ingestion jobs, you discover that CPU utilization is high in your featurestore's online serving nodes and that feature retrieval latency is high. You need to improve online serving performance during the daily batch ingestion. What should you do?
A. Schedule an increase in the number of online serving nodes in your featurestore prior to the batch ingestion jobs
B. Enable autoscaling of the online serving nodes in your featurestore
C. Enable autoscaling for the prediction nodes of your DeployedModel in the Vertex AI endpoint
D. Increase the worker_count in the ImportFeatureValues request of your batch ingestion job -
Question 188:
You lead a data science team at a large international corporation. Most of the models your team trains are large-scale models using high-level TensorFlow APIs on AI Platform with GPUs. Your team usually takes a few weeks or months to iterate on a new version of a model. You were recently asked to review your team's spending. How should you reduce your Google Cloud compute costs without impacting the model's performance?
A. Use AI Platform to run distributed training jobs with checkpoints.
B. Use AI Platform to run distributed training jobs without checkpoints.
C. Migrate to training with Kuberflow on Google Kubernetes Engine, and use preemptible VMs with checkpoints.
D. Migrate to training with Kuberflow on Google Kubernetes Engine, and use preemptible VMs without checkpoints. -
Question 189:
You need to train an XGBoost model on a small dataset. Your training code requires custom dependencies. You want to minimize the startup time of your training job. How should you set up your Vertex AI custom training job?
A. Store the data in a Cloud Storage bucket, and create a custom container with your training application. In your training application, read the data from Cloud Storage and train the model.
B. Use the XGBoost prebuilt custom container. Create a Python source distribution that includes the data and installs the dependencies at runtime. In your training application, load the data into a pandas DataFrame and train the model.
C. Create a custom container that includes the data. In your training application, load the data into a pandas DataFrame and train the model.
D. Store the data in a Cloud Storage bucket, and use the XGBoost prebuilt custom container to run your training application. Create a Python source distribution that installs the dependencies at runtime. In your training application, read the data from Cloud Storage and train the model. -
Question 190:
You have developed a BigQuery ML model that predicts customer chum, and deployed the model to Vertex AI Endpoints. You want to automate the retraining of your model by using minimal additional code when model feature values change. You also want to minimize the number of times that your model is retrained to reduce training costs. What should you do?
A. 1 Enable request-response logging on Vertex AI Endpoints 2. Schedule a TensorFlow Data Validation job to monitor prediction drift 3. Execute model retraining if there is significant distance between the distributions
B. 1. Enable request-response logging on Vertex AI Endpoints 2. Schedule a TensorFlow Data Validation job to monitor training/serving skew 3. Execute model retraining if there is significant distance between the distributions
C. 1. Create a Vertex AI Model Monitoring job configured to monitor prediction drift 2. Configure alert monitoring to publish a message to a Pub/Sub queue when a monitoring alert is detected 3. Use a Cloud Function to monitor the Pub/Sub queue, and trigger retraining in BigQuery
D. 1. Create a Vertex AI Model Monitoring job configured to monitor training/serving skew 2. Configure alert monitoring to publish a message to a Pub/Sub queue when a monitoring alert is detected 3. Use a Cloud Function to monitor the Pub/Sub queue, and trigger retraining in BigQuery
Related Exams:
-
ADWORDS-DISPLAY
Google AdWords: Display Advertising -
ADWORDS-FUNDAMENTALS
Google AdWords: Fundamentals -
ADWORDS-MOBILE
Google AdWords: Mobile Advertising -
ADWORDS-REPORTING
Google AdWords: Reporting -
ADWORDS-SEARCH
Google AdWords: Search Advertising -
ADWORDS-SHOPPING
Google AdWords: Shopping Advertising -
ADWORDS-VIDEO
Google AdWords: Video Advertising -
APIGEE-API-ENGINEER
Apigee Certified API Engineer -
ASSOCIATE-ANDROID-DEVELOPER
Associate Android Developer (Kotlin and Java) -
ASSOCIATE-CLOUD-ENGINEER
Associate Cloud Engineer
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Google exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your PROFESSIONAL-MACHINE-LEARNING-ENGINEER exam preparations and Google certification application, do not hesitate to visit our Vcedump.com to find your solutions here.