PROFESSIONAL-MACHINE-LEARNING-ENGINEER Exam Details
-
Exam Code
:PROFESSIONAL-MACHINE-LEARNING-ENGINEER -
Exam Name
:Professional Machine Learning Engineer -
Certification
:Google Certifications -
Vendor
:Google -
Total Questions
:291 Q&As -
Last Updated
:May 24, 2026
Google PROFESSIONAL-MACHINE-LEARNING-ENGINEER Online Questions & Answers
-
Question 151:
You work for an advertising company and want to understand the effectiveness of your company's latest advertising campaign. You have streamed 500 MB of campaign data into BigQuery. You want to query the table, and then manipulate the results of that query with a pandas dataframe in an AI Platform notebook. What should you do?
A. Use AI Platform Notebooks' BigQuery cell magic to query the data, and ingest the results as a pandas dataframe.
B. Export your table as a CSV file from BigQuery to Google Drive, and use the Google Drive API to ingest the file into your notebook instance.
C. Download your table from BigQuery as a local CSV file, and upload it to your AI Platform notebook instance. Use pandas.read_csv to ingest he file as a pandas dataframe.
D. From a bash cell in your AI Platform notebook, use the bq extract command to export the table as a CSV file to Cloud Storage, and then use gsutil cp to copy the data into the notebook. Use pandas.read_csv to ingest the file as a pandas dataframe. -
Question 152:
You need to design a customized deep neural network in Keras that will predict customer purchases based on their purchase history. You want to explore model performance using multiple model architectures, store training data, and be able to compare the evaluation metrics in the same dashboard. What should you do?
A. Create multiple models using AutoML Tables.
B. Automate multiple training runs using Cloud Composer.
C. Run multiple training jobs on AI Platform with similar job names.
D. Create an experiment in Kubeflow Pipelines to organize multiple runs. -
Question 153:
You developed a custom model by using Vertex AI to predict your application's user churn rate. You are using Vertex AI Model Monitoring for skew detection. The training data stored in BigQuery contains two sets of features - demographic and behavioral. You later discover that two separate models trained on each set perform better than the original model. You need to configure a new model monitoring pipeline that splits traffic among the two models. You want to use the same prediction-sampling-rate and monitoring-frequency for each model. You also want to minimize management effort. What should you do?
A. Keep the training dataset as is. Deploy the models to two separate endpoints, and submit two Vertex AI Model Monitoring jobs with appropriately selected feature-thresholds parameters.
B. Keep the training dataset as is. Deploy both models to the same endpoint and submit a Vertex AI Model Monitoring job with a monitoring-config-from-file parameter that accounts for the model IDs and feature selections.
C. Separate the training dataset into two tables based on demographic and behavioral features. Deploy the models to two separate endpoints, and submit two Vertex AI Model Monitoring jobs.
D. Separate the training dataset into two tables based on demographic and behavioral features. Deploy both models to the same endpoint, and submit a Vertex AI Model Monitoring job with a monitoring-config-from-file parameter that accounts for the model IDs and training datasets. -
Question 154:
You are an ML engineer at a manufacturing company. You need to build a model that identifies defects in products based on images of the product taken at the end of the assembly line. You want your model to preprocess the images with lower computation to quickly extract features of defects in products. Which approach should you use to build the model?
A. Reinforcement learning
B. Recommender system
C. Recurrent Neural Networks (RNN)
D. Convolutional Neural Networks (CNN) -
Question 155:
You work at a large organization that recently decided to move their ML and data workloads to Google Cloud. The data engineering team has exported the structured data to a Cloud Storage bucket in Avro format. You need to propose a workflow that performs analytics, creates features, and hosts the features that your ML models use for online prediction. How should you configure the pipeline?
A. Ingest the Avro files into Cloud Spanner to perform analytics. Use a Dataflow pipeline to create the features, and store them in Vertex AI Feature Store for online prediction.
B. Ingest the Avro files into BigQuery to perform analytics. Use a Dataflow pipeline to create the features, and store them in Vertex AI Feature Store for online prediction.
C. Ingest the Avro files into Cloud Spanner to perform analytics. Use a Dataflow pipeline to create the features, and store them in BigQuery for online prediction.
D. Ingest the Avro files into BigQuery to perform analytics. Use BigQuery SQL to create features and store them in a separate BigQuery table for online prediction. -
Question 156:
You are building a TensorFlow text-to-image generative model by using a dataset that contains billions of images with their respective captions. You want to create a low maintenance, automated workflow that reads the data from a Cloud Storage bucket collects statistics, splits the dataset into training/validation/test datasets performs data transformations trains the model using the training/validation datasets, and validates the model by using the test dataset. What should you do?
A. Use the Apache Airflow SDK to create multiple operators that use Dataflow and Vertex AI services. Deploy the workflow on Cloud Composer.
B. Use the MLFlow SDK and deploy it on a Google Kubernetes Engine cluster. Create multiple components that use Dataflow and Vertex AI services.
C. Use the Kubeflow Pipelines (KFP) SDK to create multiple components that use Dataflow and Vertex AI services. Deploy the workflow on Vertex AI Pipelines.
D. Use the TensorFlow Extended (TFX) SDK to create multiple components that use Dataflow and Vertex AI services. Deploy the workflow on Vertex AI Pipelines. -
Question 157:
Your work for a textile manufacturing company. Your company has hundreds of machines, and each machine has many sensors. Your team used the sensory data to build hundreds of ML models that detect machine anomalies. Models are retrained daily, and you need to deploy these models in a cost-effective way. The models must operate 24/7 without downtime and make sub millisecond predictions. What should you do?
A. Deploy a Dataflow batch pipeline and a Vertex AI Prediction endpoint.
B. Deploy a Dataflow batch pipeline with the Runlnference API, and use model refresh.
C. Deploy a Dataflow streaming pipeline and a Vertex AI Prediction endpoint with autoscaling.
D. Deploy a Dataflow streaming pipeline with the Runlnference API, and use automatic model refresh. -
Question 158:
You work for an organization that operates a streaming music service. You have a custom production model that is serving a “next song” recommendation based on a user's recent listening history. Your model is deployed on a Vertex AI endpoint. You recently retrained the same model by using fresh data. The model received positive test results offline. You now want to test the new model in production while minimizing complexity. What should you do?
A. Create a new Vertex AI endpoint for the new model and deploy the new model to that new endpoint. Build a service to randomly send 5% of production traffic to the new endpoint. Monitor end-user metrics such as listening time. If end-user metrics improve between models over time, gradually increase the percentage of production traffic sent to the new endpoint.
B. Capture incoming prediction requests in BigQuery. Create an experiment in Vertex AI Experiments. Run batch predictions for both models using the captured data. Use the user's selected song to compare the models performance side by side. If the new model's performance metrics are better than the previous model, deploy the new model to production.
C. Deploy the new model to the existing Vertex AI endpoint. Use traffic splitting to send 5% of production traffic to the new model. Monitor end-user metrics, such as listening time. If end-user metrics improve between models over time, gradually increase the percentage of production traffic sent to the new model.
D. Configure a model monitoring job for the existing Vertex AI endpoint. Configure the monitoring job to detect prediction drift and set a threshold for alerts. Update the model on the endpoint from the previous model to the new model. If you receive an alert of prediction drift, revert to the previous model. -
Question 159:
You are designing an architecture with a serverless ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
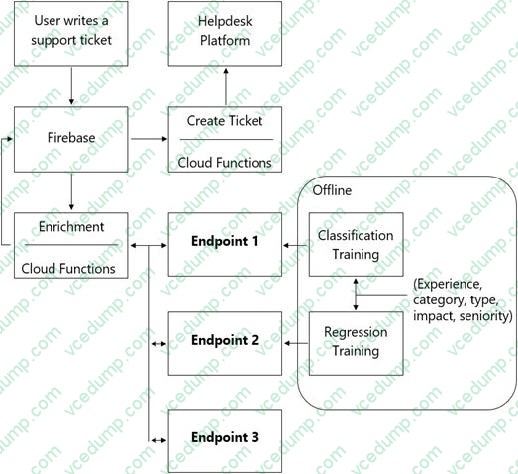
Which endpoints should the Enrichment Cloud Functions call?
A. 1 = AI Platform, 2 = AI Platform, 3 = AutoML Vision
B. 1 = AI Platform, 2 = AI Platform, 3 = AutoML Natural Language
C. 1 = AI Platform, 2 = AI Platform, 3 = Cloud Natural Language API
D. 1 = Cloud Natural Language API, 2 = AI Platform, 3 = Cloud Vision API -
Question 160:
You work at a bank. You need to develop a credit risk model to support loan application decisions. You decide to implement the model by using a neural network in TensorFlow. Due to regulatory requirements, you need to be able to explain the model's predictions based on its features. When the model is deployed, you also want to monitor the model's performance over time. You decided to use Vertex AI for both model development and deployment. What should you do?
A. Use Vertex Explainable AI with the sampled Shapley method, and enable Vertex AI Model Monitoring to check for feature distribution drift.
B. Use Vertex Explainable AI with the sampled Shapley method, and enable Vertex AI Model Monitoring to check for feature distribution skew.
C. Use Vertex Explainable AI with the XRAI method, and enable Vertex AI Model Monitoring to check for feature distribution drift.
D. Use Vertex Explainable AI with the XRAI method, and enable Vertex AI Model Monitoring to check for feature distribution skew.
Related Exams:
-
ADWORDS-DISPLAY
Google AdWords: Display Advertising -
ADWORDS-FUNDAMENTALS
Google AdWords: Fundamentals -
ADWORDS-MOBILE
Google AdWords: Mobile Advertising -
ADWORDS-REPORTING
Google AdWords: Reporting -
ADWORDS-SEARCH
Google AdWords: Search Advertising -
ADWORDS-SHOPPING
Google AdWords: Shopping Advertising -
ADWORDS-VIDEO
Google AdWords: Video Advertising -
APIGEE-API-ENGINEER
Apigee Certified API Engineer -
ASSOCIATE-ANDROID-DEVELOPER
Associate Android Developer (Kotlin and Java) -
ASSOCIATE-CLOUD-ENGINEER
Associate Cloud Engineer
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Google exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your PROFESSIONAL-MACHINE-LEARNING-ENGINEER exam preparations and Google certification application, do not hesitate to visit our Vcedump.com to find your solutions here.