PROFESSIONAL-DATA-ENGINEER Exam Details
-
Exam Code
:PROFESSIONAL-DATA-ENGINEER -
Exam Name
:Professional Data Engineer on Google Cloud Platform -
Certification
:Google Certifications -
Vendor
:Google -
Total Questions
:331 Q&As -
Last Updated
:Jun 24, 2026
Google PROFESSIONAL-DATA-ENGINEER Online Questions & Answers
-
Question 151:
Your neural network model is taking days to train. You want to increase the training speed. What can you do?
A. Subsample your test dataset.
B. Subsample your training dataset.
C. Increase the number of input features to your model.
D. Increase the number of layers in your neural network.
-
Question 152:
Your company receives both batch- and stream-based event data. You want to process the data using Google Cloud Dataflow over a predictable time period. However, you realize that in some instances data can arrive late or out of order. How should you design your Cloud Dataflow pipeline to handle data that is late or out of order?
A. Set a single global window to capture all the data.
B. Set sliding windows to capture all the lagged data.
C. Use watermarks and timestamps to capture the lagged data.
D. Ensure every datasource type (stream or batch) has a timestamp, and use the timestamps to define the logic for lagged data.
-
Question 153:
You are migrating a large number of files from a public HTTPS endpoint to Cloud Storage. The files are protected from unauthorized access using signed URLs. You created a TSV file that contains the list of object URLs and started a transfer job by using Storage Transfer Service. You notice that the job has run for a long time and eventually failed Checking the logs of the transfer job reveals that the job was running fine until one point, and then it failed due to HTTP 403 errors on the remaining files You verified that there were no changes to the source system You need to fix the problem to resume the migration process. What should you do?
A. Set up Cloud Storage FUSE, and mount the Cloud Storage bucket on a Compute Engine Instance Remove the completed files from the TSV file Use a shell script to iterate through the TSV file and download the remaining URLs to the FUSE mount point.
B. Update the file checksums in the TSV file from using MD5 to SHA256. Remove the completed files from the TSV file and rerun the Storage Transfer Service job.
C. Renew the TLS certificate of the HTTPS endpoint Remove the completed files from the TSV file and rerun the Storage Transfer Service job.
D. Create a new TSV file for the remaining files by generating signed URLs with a longer validity period. Split the TSV file into multiple smaller files and submit them as separate Storage Transfer Service jobs in parallel.
-
Question 154:
A TensorFlow machine learning model on Compute Engine virtual machines (n2-standard 32) takes two days to complete framing. The model has custom TensorFlow operations that must run partially on a CPU You want to reduce the training time in a cost-effective manner. What should you do?
A. Change the VM type to n2-highmem-32
B. Change the VM type to e2 standard-32
C. Train the model using a VM with a GPU hardware accelerator
D. Train the model using a VM with a TPU hardware accelerator
-
Question 155:
You are designing a system that requires an ACID-compliant database. You must ensure that the system requires minimal human intervention in case of a failure. What should you do?
A. Configure a Cloud SQL for MySQL instance with point-in-time recovery enabled.
B. Configure a Cloud SQL for PostgreSQL instance with high availability enabled.
C. Configure a Bigtable instance with more than one cluster.
D. Configure a BJgQuery table with a multi-region configuration.
-
Question 156:
You work for a manufacturing company that sources up to 750 different components, each from a different supplier. You've collected a labeled dataset that has on average 1000 examples for each unique component. Your team wants to implement an app to help warehouse workers recognize incoming components based on a photo of the component. You want to implement the first working version of this app (as Proof-Of-Concept) within a few working days. What should you do?
A. Use Cloud Vision AutoML with the existing dataset.
B. Use Cloud Vision AutoML, but reduce your dataset twice.
C. Use Cloud Vision API by providing custom labels as recognition hints.
D. Train your own image recognition model leveraging transfer learning techniques.
-
Question 157:
You are developing a model to identify the factors that lead to sales conversions for your customers. You have completed processing your data. You want to continue through the model development lifecycle. What should you do next?
A. Use your model to run predictions on fresh customer input data.
B. Test and evaluate your model on your curated data to determine how well the model performs.
C. Monitor your model performance, and make any adjustments needed.
D. Delineate what data will be used for testing and what will be used for training the model.
-
Question 158:
Your team is responsible for developing and maintaining ETLs in your company. One of your Dataflow jobs is failing because of some errors in the input data, and you need to improve reliability of the pipeline (incl. being able to reprocess all failing data).
What should you do?
A. Add a filtering step to skip these types of errors in the future, extract erroneous rows from logs.
B. Add a try... catch block to your DoFn that transforms the data, extract erroneous rows from logs.
C. Add a try... catch block to your DoFn that transforms the data, write erroneous rows to PubSub directly from the DoFn.
D. Add a try... catch block to your DoFn that transforms the data, use a sideOutput to create a PCollection that can be stored to PubSub later.
-
Question 159:
The Development and External teams nave the project viewer Identity and Access Management (1AM) role m a folder named Visualization. You want the Development Team to be able to read data from both Cloud Storage and BigQuery, but the External Team should only be able to read data from BigQuery. What should you do?
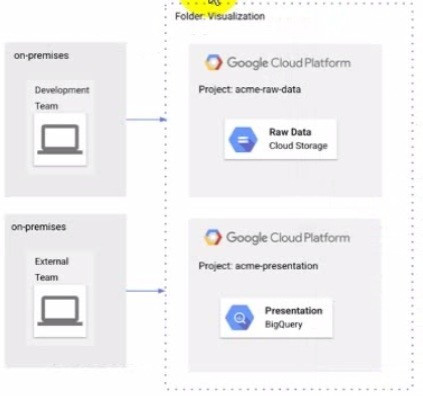
A. Remove Cloud Storage IAM permissions to the External Team on the acme-raw-data project
B. Create Virtual Private Cloud (VPC) firewall rules on the acme-raw-data protect that deny all Ingress traffic from the External Team CIDR range
C. Create a VPC Service Controls perimeter containing both protects and BigQuery as a restricted API Add the External Team users to the perimeter s Access Level
D. Create a VPC Service Controls perimeter containing both protects and Cloud Storage as a restricted API. Add the Development Team users to the perimeter's Access Level
-
Question 160:
You are running a pipeline in Cloud Dataflow that receives messages from a Cloud Pub/Sub topic and writes the results to a BigQuery dataset in the EU. Currently, your pipeline is located in europe-west4 and has a maximum of 3 workers, instance type n1- standard-1. You notice that during peak periods, your pipeline is struggling to process records in a timely fashion, when all 3 workers are at maximum CPU utilization. Which two actions can you take to increase performance of your pipeline? (Choose two.)
A. Increase the number of max workers
B. Use a larger instance type for your Cloud Dataflow workers
C. Change the zone of your Cloud Dataflow pipeline to run in us-central1
D. Create a temporary table in Cloud Bigtable that will act as a buffer for new data. Create a new step in your pipeline to write to this table first, and then create a new pipeline to write from Cloud Bigtable to BigQuery
E. Create a temporary table in Cloud Spanner that will act as a buffer for new data. Create a new step in your pipeline to write to this table first, and then create a new pipeline to write from Cloud Spanner to BigQuery
Related Exams:
-
ADWORDS-DISPLAY
Google AdWords: Display Advertising -
ADWORDS-FUNDAMENTALS
Google AdWords: Fundamentals -
ADWORDS-MOBILE
Google AdWords: Mobile Advertising -
ADWORDS-REPORTING
Google AdWords: Reporting -
ADWORDS-SEARCH
Google AdWords: Search Advertising -
ADWORDS-SHOPPING
Google AdWords: Shopping Advertising -
ADWORDS-VIDEO
Google AdWords: Video Advertising -
APIGEE-API-ENGINEER
Apigee Certified API Engineer -
ASSOCIATE-ANDROID-DEVELOPER
Associate Android Developer (Kotlin and Java) -
ASSOCIATE-CLOUD-ENGINEER
Associate Cloud Engineer
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Google exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your PROFESSIONAL-DATA-ENGINEER exam preparations and Google certification application, do not hesitate to visit our Vcedump.com to find your solutions here.