PROFESSIONAL-DATA-ENGINEER Exam Details
-
Exam Code
:PROFESSIONAL-DATA-ENGINEER -
Exam Name
:Professional Data Engineer on Google Cloud Platform -
Certification
:Google Certifications -
Vendor
:Google -
Total Questions
:331 Q&As -
Last Updated
:Jun 24, 2026
Google PROFESSIONAL-DATA-ENGINEER Online Questions & Answers
-
Question 111:
You are migrating a table to BigQuery and are deeding on the data model. Your table stores information related to purchases made across several store locations and includes information like the time of the transaction, items purchased, the store ID and the city and state in which the store is located You frequently query this table to see how many of each item were sold over the past 30 days and to look at purchasing trends by state city and individual store. You want to model this table to minimize query time and cost. What should you do?
A. Partition by transaction time; cluster by state first, then city then store ID
B. Partition by transaction tome cluster by store ID first, then city, then stale
C. Top-level cluster by stale first, then city then store
D. Top-level cluster by store ID first, then city then state.
-
Question 112:
Your company maintains a hybrid deployment with GCP, where analytics are performed on your anonymized customer data. The data are imported to Cloud Storage from your data center through parallel uploads to a data transfer server running on GCP. Management informs you that the daily transfers take too long and have asked you to fix the problem. You want to maximize transfer speeds. Which action should you take?
A. Increase the CPU size on your server.
B. Increase the size of the Google Persistent Disk on your server.
C. Increase your network bandwidth from your datacenter to GCP.
D. Increase your network bandwidth from Compute Engine to Cloud Storage.
-
Question 113:
Your company is selecting a system to centralize data ingestion and delivery. You are considering messaging and data integration systems to address the requirements. The key requirements are:
1.
The ability to seek to a particular offset in a topic, possibly back to the start of all data ever captured
2.
Support for publish/subscribe semantics on hundreds of topics Retain per-key ordering
Which system should you choose?
A. Apache Kafka
B. Cloud Storage
C. Cloud Pub/Sub
D. Firebase Cloud Messaging
-
Question 114:
You use a dataset in BigQuery for analysis. You want to provide third-party companies with access to the same dataset. You need to keep the costs of data sharing low and ensure that the data is current. What should you do?
A. Use Analytics Hub to control data access, and provide third party companies with access to the dataset
B. Create a Dataflow job that reads the data in frequent time intervals and writes it to the relevant BigQuery dataset or Cloud Storage bucket for third-party companies to use.
C. Use Cloud Scheduler to export the data on a regular basis to Cloud Storage, and provide third-party companies with access to the bucket.
D. Create a separate dataset in BigQuery that contains the relevant data to share, and provide third-party companies with access to the new dataset.
-
Question 115:
You plan to deploy Cloud SQL using MySQL. You need to ensure high availability in the event of a zone failure. What should you do?
A. Create a Cloud SQL instance in one zone, and create a failover replica in another zone within the same region.
B. Create a Cloud SQL instance in one zone, and create a read replica in another zone within the same region.
C. Create a Cloud SQL instance in one zone, and configure an external read replica in a zone in a different region.
D. Create a Cloud SQL instance in a region, and configure automatic backup to a Cloud Storage bucket in the same region.
-
Question 116:
Your company's data platform ingests CSV file dumps of booking and user profile data from upstream sources into Cloud Storage. The data analyst team wants to join these datasets on the email field available in both the datasets to perform analysis. However, personally identifiable information (PII) should not be accessible to the analysts. You need to de-identify the email field in both the datasets before loading them into BigQuery for analysts. What should you do?
A. 1. Create a pipeline to de-identify the email field by using recordTransformations in Cloud Data Loss Prevention (Cloud DLP) with masking as the de-identification transformations type.
2. Load the booking and user profile data into a BigQuery table.
B. 1. Create a pipeline to de-identify the email field by using recordTransformations in Cloud DLP with format-preserving encryption with FFX as the de-identification transformation type.
2. Load the booking and user profile data into a BigQuery table.
C. 1. Load the CSV files from Cloud Storage into a BigQuery table, and enable dynamic data masking.
2.
Create a policy tag with the email mask as the data masking rule.
3.
Assign the policy to the email field in both tables. A
4.
Assign the Identity and Access Management bigquerydatapolicy.maskedReader role for the BigQuery tables to the analysts.
D. 1. Load the CSV files from Cloud Storage into a BigQuery table, and enable dynamic data masking.
2.
Create a policy tag with the default masking value as the data masking rule.
3.
Assign the policy to the email field in both tables.
4.
Assign the Identity and Access Management bigquerydatapolicy.maskedReader role for the BigQuery tables to the analysts
-
Question 117:
You want to create a machine learning model using BigQuery ML and create an endpoint foe hosting the model using Vertex Al. This will enable the processing of continuous streaming data in near-real time from multiple vendors. The data may contain invalid values. What should you do?
A. Create a new BigOuery dataset and use streaming inserts to land the data from multiple vendors. Configure your BigQuery ML model to use the "ingestion' dataset as the training data.
B. Use BigQuery streaming inserts to land the data from multiple vendors whore your BigQuery dataset ML model is deployed.
C. Create a Pub'Sub topic and send all vendor data to it Connect a Cloud Function to the topic to process the data and store it in BigQuery.
D. Create a Pub/Sub topic and send all vendor data to it Use Dataflow to process and sanitize the Pub/Sub data and stream it to BigQuery.
-
Question 118:
You store and analyze your relational data in BigQuery on Google Cloud with all data that resides in US regions. You also have a variety of object stores across Microsoft Azure and Amazon Web Services (AWS), also in US regions. You want to query all your data in BigQuery daily with as little movement of data as possible. What should you do?
A. Load files from AWS and Azure to Cloud Storage with Cloud Shell gautil rsync arguments.
B. Create a Dataflow pipeline to ingest files from Azure and AWS to BigQuery.
C. Use the BigQuery Omni functionality and BigLake tables to query files in Azure and AWS.
D. Use BigQuery Data Transfer Service to load files from Azure and AWS into BigQuery.
-
Question 119:
You have some data, which is shown in the graphic below. The two dimensions are X and Y, and the shade of each dot represents what class it is. You want to classify this data accurately using a linear algorithm.
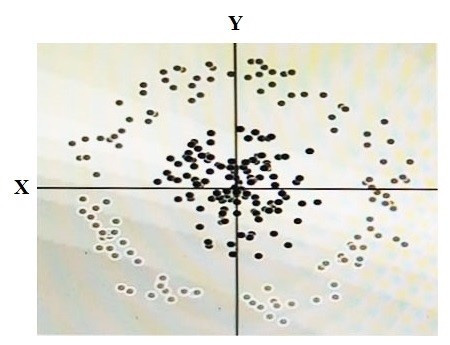
To do this you need to add a synthetic feature. What should the value of that feature be?
A. X^2+Y^2
B. X^2
C. Y^2
D. cos(X)
-
Question 120:
You are building an ELT solution in BigQuery by using Dataform. You need to perform uniqueness and null value checks on your final tables. What should you do to efficiently integrate these checks into your pipeline?
A. Build Dataform assertions into your code
B. Write a Spark-based stored procedure.
C. Build BigQuery user-defined functions (UDFs).
D. Create Dataplex data quality tasks.
Related Exams:
-
ADWORDS-DISPLAY
Google AdWords: Display Advertising -
ADWORDS-FUNDAMENTALS
Google AdWords: Fundamentals -
ADWORDS-MOBILE
Google AdWords: Mobile Advertising -
ADWORDS-REPORTING
Google AdWords: Reporting -
ADWORDS-SEARCH
Google AdWords: Search Advertising -
ADWORDS-SHOPPING
Google AdWords: Shopping Advertising -
ADWORDS-VIDEO
Google AdWords: Video Advertising -
APIGEE-API-ENGINEER
Apigee Certified API Engineer -
ASSOCIATE-ANDROID-DEVELOPER
Associate Android Developer (Kotlin and Java) -
ASSOCIATE-CLOUD-ENGINEER
Associate Cloud Engineer
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Google exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your PROFESSIONAL-DATA-ENGINEER exam preparations and Google certification application, do not hesitate to visit our Vcedump.com to find your solutions here.