DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK Exam Details
-
Exam Code
:DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK -
Exam Name
:Databricks Certified Associate Developer for Apache Spark 3.0 -
Certification
:Databricks Certifications -
Vendor
:Databricks -
Total Questions
:180 Q&As -
Last Updated
:Jul 12, 2026
Databricks DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK Online Questions & Answers
-
Question 121:
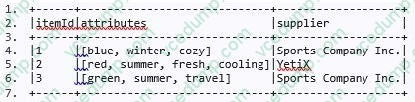
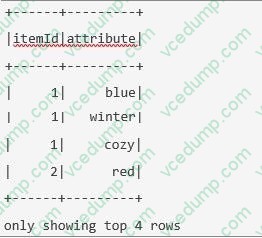
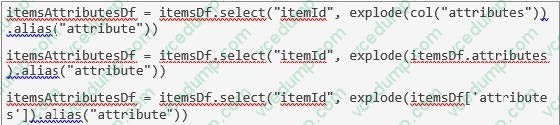
The code block displayed below contains an error. The code block should create DataFrame itemsAttributesDf which has columns itemId and attribute and lists every attribute from the attributes column in DataFrame itemsDf next to the itemId of the respective row in itemsDf. Find the error.
A sample of DataFrame itemsDf is below.
Code block:
itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")
A. Since itemId is the index, it does not need to be an argument to the select() method.
B. The alias() method needs to be called after the select() method.
C. The explode() method expects a Column object rather than a string.
D. explode() is not a method of DataFrame. explode() should be used inside the select() method instead.
E. The split() method should be used inside the select() method instead of the explode() method. -
Question 122:
Which of the following describes the difference between client and cluster execution modes?
A. In cluster mode, the driver runs on the worker nodes, while the client mode runs the driver on the client machine.
B. In cluster mode, the driver runs on the edge node, while the client mode runs the driver in a worker node.
C. In cluster mode, each node will launch its own executor, while in client mode, executors will exclusively run on the client machine.
D. In client mode, the cluster manager runs on the same host as the driver, while in cluster mode, the cluster manager runs on a separate node.
E. In cluster mode, the driver runs on the master node, while in client mode, the driver runs on a virtual machine in the cloud. -
Question 123:
Which of the following code blocks returns a copy of DataFrame transactionsDf in which column productId has been renamed to productNumber?
A. transactionsDf.withColumnRenamed("productId", "productNumber")
B. transactionsDf.withColumn("productId", "productNumber")
C. transactionsDf.withColumnRenamed("productNumber", "productId")
D. transactionsDf.withColumnRenamed(col(productId), col(productNumber))
E. transactionsDf.withColumnRenamed(productId, productNumber) -
Question 124:
The code block shown below should return a single-column DataFrame with a column named consonant_ct that, for each row, shows the number of consonants in column itemName of DataFrame
itemsDf. Choose the answer that correctly fills the blanks in the code block to accomplish this.
DataFrame itemsDf:
1.+------+----------------------------------+-----------------------------+-------------------+
2.|itemId|itemName |attributes |supplier |
3.+------+----------------------------------+-----------------------------+-------------------+
4.|1 |Thick Coat for Walking in the Snow|[blue, winter, cozy] |Sports Company Inc.|
5.|2 |Elegant Outdoors Summer Dress |[red, summer, fresh, cooling]|YetiX |
6.|3 |Outdoors Backpack |[green, summer, travel] |Sports Company Inc.|
7.+------+----------------------------------+-----------------------------+-------------------+
Code block:
itemsDf.select(__1__(__2__(__3__(__4__), "a|e|i|o|u|\s", "")).__5__("consonant_ct"))
A. 1. length 2. regexp_extract 3. upper 4. col("itemName") 5. as
B. 1. size 2. regexp_replace 3. lower 4. "itemName" 5. alias
C. 1. lower 2. regexp_replace 3. length 4. "itemName" 5. alias
D. 1. length 2. regexp_replace 3. lower 4. col("itemName") 5. alias
E. 1. size 2. regexp_extract 3. lower 4. col("itemName") 5. alias -
Question 125:
Which of the following statements about RDDs is incorrect?
A. An RDD consists of a single partition.
B. The high-level DataFrame API is built on top of the low-level RDD API.
C. RDDs are immutable.
D. RDD stands for Resilient Distributed Dataset.
E. RDDs are great for precisely instructing Spark on how to do a query. -
Question 126:
Which of the following code blocks returns a DataFrame that matches the multi-column DataFrame itemsDf, except that integer column itemId has been converted into a string column?
A. itemsDf.withColumn("itemId", convert("itemId", "string"))
B. itemsDf.withColumn("itemId", col("itemId").cast("string"))
C. itemsDf.select(cast("itemId", "string"))
D. itemsDf.withColumn("itemId", col("itemId").convert("string"))
E. spark.cast(itemsDf, "itemId", "string") -
Question 127:
The code block shown below should write DataFrame transactionsDf to disk at path csvPath as a single CSV file, using tabs (\t characters) as separators between columns, expressing missing
values as string n/a, and omitting a header row with column names. Choose the answer that correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__.write.__2__(__3__, " ").__4__.__5__(csvPath)
A. 1. coalesce(1) 2. option 3. "sep" 4. option("header", True) 5. path
B. 1. coalesce(1) 2. option 3. "colsep" 4. option("nullValue", "n/a") 5. path
C. 1. repartition(1) 2. option 3. "sep" 4. option("nullValue", "n/a") 5. csv
D. 1. csv 2. option 3. "sep" 4. option("emptyValue", "n/a") 5. path ? 1. repartition(1) 2. mode 3. "sep" 4. mode("nullValue", "n/a") 5. csv -
Question 128:
The code block shown below should return only the average prediction error (column predError) of a random subset, without replacement, of approximately 15% of rows in DataFrame transactionsDf. Choose the answer that correctly fills the blanks in the code block to accomplish this.
transactionsDf.__1__(__2__, __3__).__4__(avg('predError'))
A. 1. sample 2. True 3. 0.15 4. filter
B. 1. sample 2. False 3. 0.15 4. select
C. 1. sample 2. 0.85 3. False 4. select
D. 1. fraction 2. 0.15 3. True 4. where
E. 1. fraction 2. False 3. 0.85 4. select -
Question 129:
Which of the following code blocks returns a one-column DataFrame for which every row contains an array of all integer numbers from 0 up to and including the number given in column predError of DataFrame transactionsDf, and null if predError is null?
Sample of DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 1| 3| 4| 25| 1|null|
5.| 2| 6| 7| 2| 2|null|
6.| 3| 3| null| 25| 3|null|
7.| 4| null| null| 3| 2|null|
8.| 5| null| null| null| 2|null|
9.| 6| 3| 2| 25| 2|null|
10.+-------------+---------+-----+-------+---------+----+
A. 1.def count_to_target(target): 2. if target is None: 3. return 4. 5. result = [range(target)] 6. return result 7. 8.count_to_target_udf = udf(count_to_target, ArrayType[IntegerType]) 9. 10.transactionsDf.select(count_to_target_udf(col('predError')))
B. 1.def count_to_target(target): 2. if target is None: 3. return 4. 5. result = list(range(target)) 6. return result 7. 8.transactionsDf.select(count_to_target(col('predError')))
C. 1.def count_to_target(target): 2. if target is None: 3. return 4. 5. result = list(range(target)) 6. return result 7. 8.count_to_target_udf = udf(count_to_target, ArrayType(IntegerType())) 9. 10.transactionsDf.select(count_to_target_udf('predError')) (Correct)
D. 1.def count_to_target(target): 2. result = list(range(target)) 3. return result 4. 5.count_to_target_udf = udf(count_to_target, ArrayType(IntegerType())) 6. 7.df = transactionsDf.select(count_to_target_udf('predError'))
E. 1.def count_to_target(target): 2. if target is None: 3. return 4. 5. result = list(range(target)) 6. return result 7. 8.count_to_target_udf = udf(count_to_target) 9. 10.transactionsDf.select(count_to_target_udf('predError')) -
Question 130:
Which of the following code blocks returns a copy of DataFrame itemsDf where the column supplier has been renamed to manufacturer?
A. itemsDf.withColumn(["supplier", "manufacturer"])
B. itemsDf.withColumn("supplier").alias("manufacturer")
C. itemsDf.withColumnRenamed("supplier", "manufacturer")
D. itemsDf.withColumnRenamed(col("manufacturer"), col("supplier"))
E. itemsDf.withColumnsRenamed("supplier", "manufacturer")

Related Exams:
-
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK
Databricks Certified Associate Developer for Apache Spark 3.0 -
DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK-35
Databricks Certified Associate Developer for Apache Spark 3.5 - Python -
DATABRICKS-CERTIFIED-DATA-ANALYST-ASSOCIATE
Databricks Certified Data Analyst Associate -
DATABRICKS-CERTIFIED-DATA-ENGINEER-ASSOCIATE
Databricks Certified Data Engineer Associate -
DATABRICKS-CERTIFIED-GENERATIVE-AI-ENGINEER-ASSOCIATE
Databricks Certified Generative AI Engineer Associate -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-ENGINEER
Databricks Certified Data Engineer Professional -
DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST
Databricks Certified Professional Data Scientist -
DATABRICKS-MACHINE-LEARNING-ASSOCIATE
Databricks Certified Machine Learning Associate -
DATABRICKS-MACHINE-LEARNING-PROFESSIONAL
Databricks Certified Machine Learning Professional
Tips on How to Prepare for the Exams
Nowadays, the certification exams become more and more important and required by more and more enterprises when applying for a job. But how to prepare for the exam effectively? How to prepare for the exam in a short time with less efforts? How to get a ideal result and how to find the most reliable resources? Here on Vcedump.com, you will find all the answers. Vcedump.com provide not only Databricks exam questions, answers and explanations but also complete assistance on your exam preparation and certification application. If you are confused on your DATABRICKS-CERTIFIED-ASSOCIATE-DEVELOPER-FOR-APACHE-SPARK exam preparations and Databricks certification application, do not hesitate to visit our Vcedump.com to find your solutions here.